


Big Tech is Big Spending + The Implications of Said Spending on the Intelligence Explosion

I wrote a post in December of 2022 where I went through some of the eye catching statistics about just how big “Big Tech” is (was at the time). Note the market caps of each of these companies has since mooned:
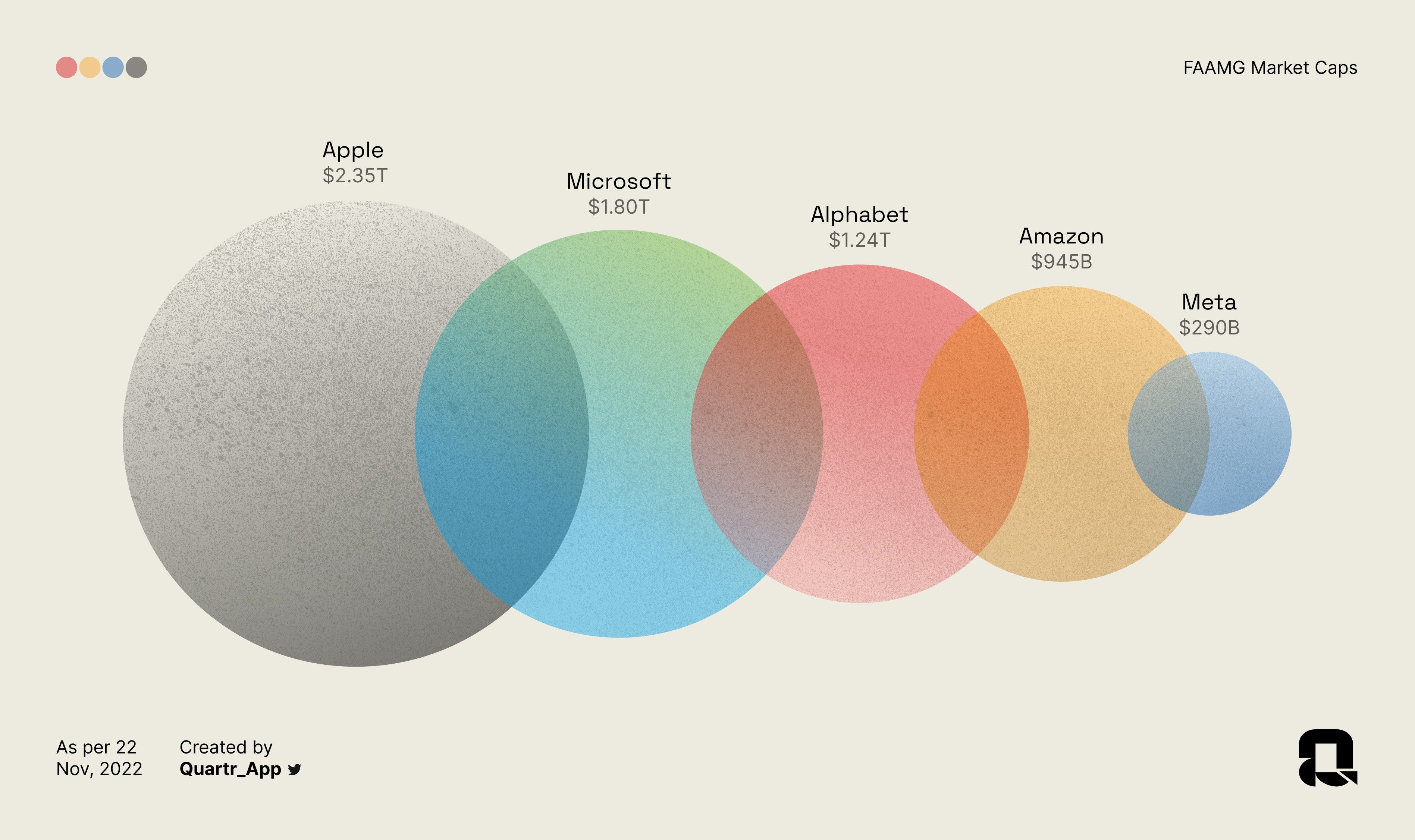
Apple is now $3.7T
Microsoft is now $3.1T
Google: $2.4T
Amazon: $2.4T
Meta: $1.5T
The collective growth is around $6.5T and their total market cap is now ~$13T - around 5.5X what the entire stock market of Germany is worth.
It might surprise you (if you haven’t read my other piece, linked here) that the five companies above are also the five largest spenders on R&D and Capex - larger than oil giants and pharmaceutical companies - the prior record holders. Microsoft will spend more on capex next year than ALL OIL MAJORS COMBINED.
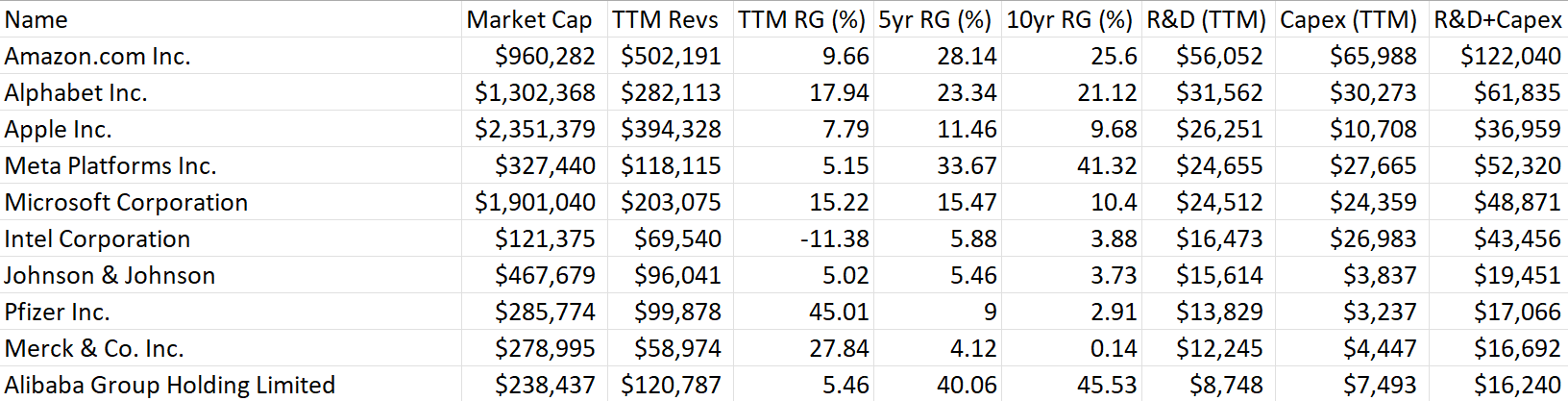
Here’s another outdated table showing just how much Big Tech already dominated “investing in the future” - which both R&D and Capex represent (updated table after):
And Oh My! How those figures have grown…
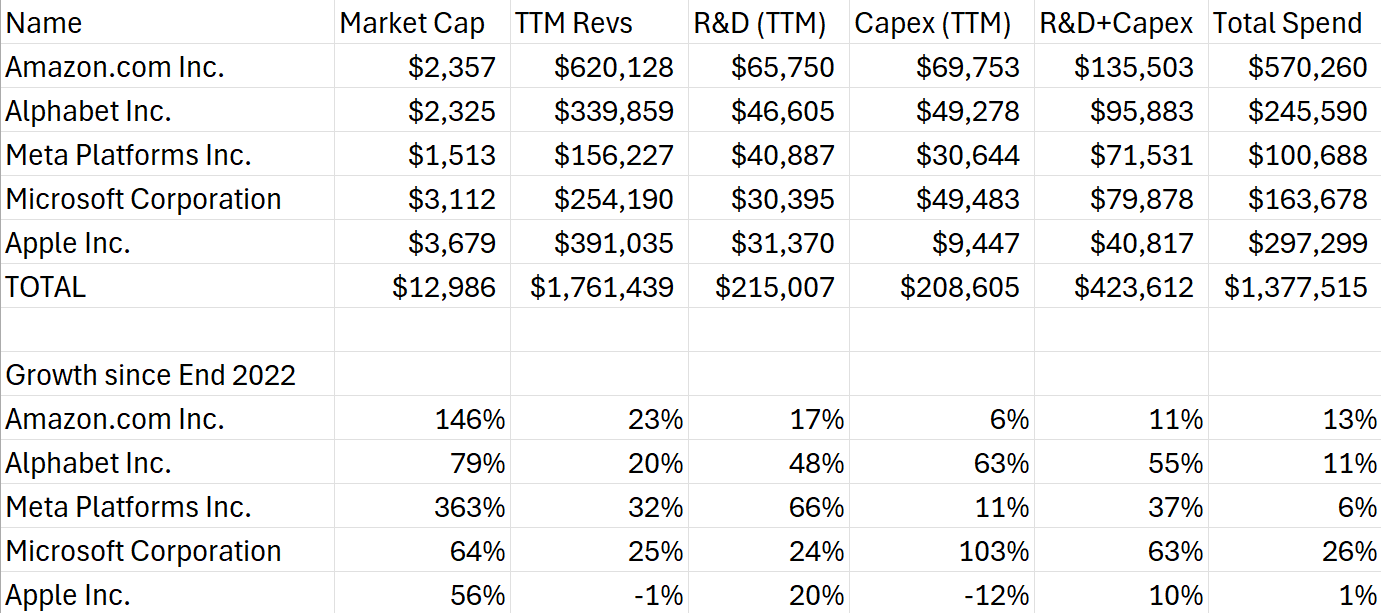
The amount of money a company has to spend is in many ways a proxy for its influence. “I can build my factory here, I can hire more people there” and so on…
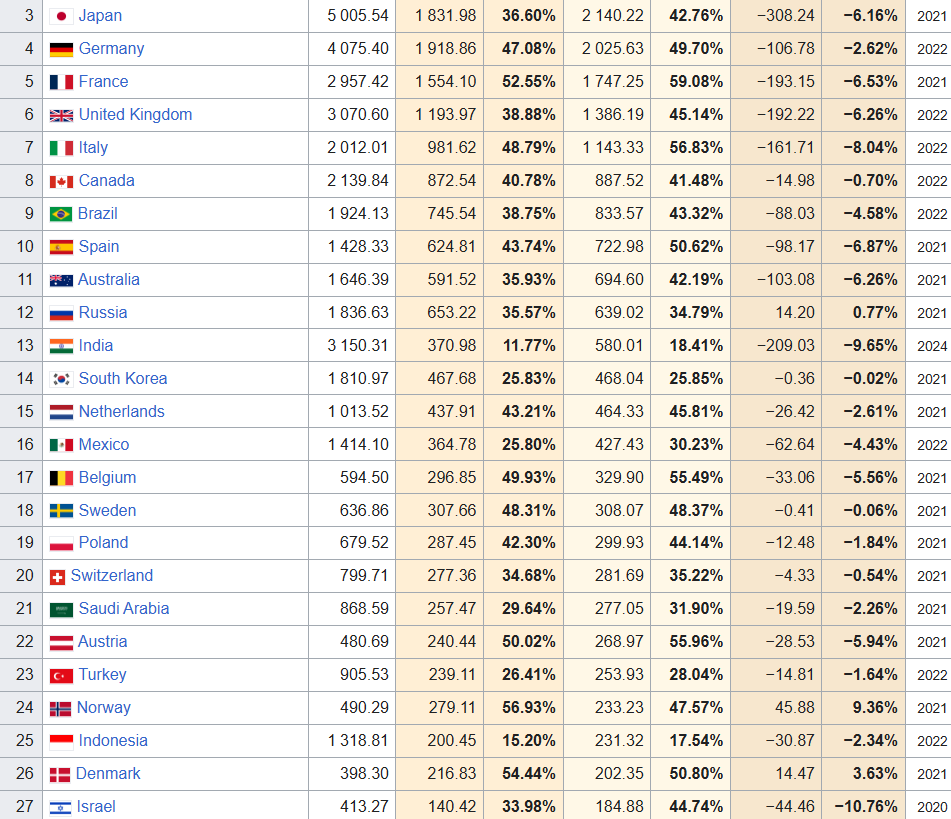
The below data is mostly from 2021-2022, but the point holds. These companies are spending as much money as entire countries - every single year. Collectively, their spending in 2024 was larger than the spending of all but five countries’ (US, China, Japan, Germany, France) circa 2021/2022. The fourth column from left is spending in billions USD.
What’s even crazier is that growth is accelerating. Twitter is blowing up after Microsoft announced Friday that they intend to spend $80B building data centers next year:
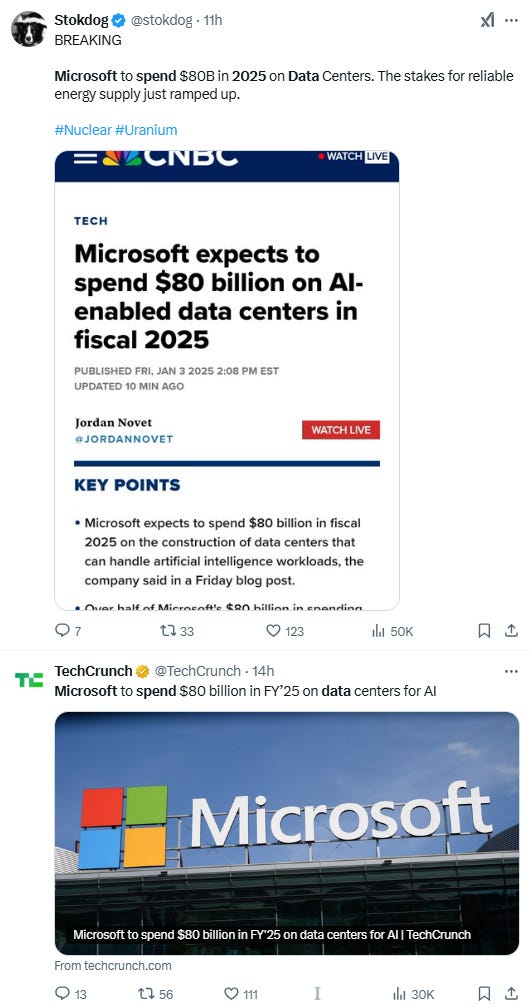
Put differently, Microsoft will spend as much money building data centers next year as will the governments of Hong Kong or Vietnam spend on everything.
But what does it all mean? Two takeaways:
#1 All of Big Tech (except maybe Apple) believes that everything is about to change. They believe AGI is coming and is imminent. They’re spending this amount of money out of a combination of fear and excitement. Fear that others will have more powerful tools to compete in a world with intelligent machines, but excitement at the prospect of how much their companies will be worth if they can establish themselves in the coming age of AGI, excitement at the prospect of becoming immortal and having their names written down in history books as members of the Technocracy who ushered in The Era of Intelligent Machines.
Microsoft has historically been more reluctant to take risks than anyone on the list but Apple. My personal view after listening to most of Satya’s recent interviews is that he doesn’t even perceive himself as taking unusual amounts of risk. He thinks the likelihood of demand being there for the “intelligence machine” he’s building out is extremely high. If he is correct then Big Tech is still - obviously - undervalued relative to the market (as a basket)…Do you know better than daddy Satya, young Padawan?
Brief Aside: Remember that whether or not something is undervalued can only be known with certainty by looking back from some point in the future. The only true definition of “undervalued” is - [it outperformed over the period].
The people best positioned to know whether AGI is around the corner are employees in Google Intelligence (DeepMind), OpenAI, etc. The debate recently has shifted from whether or not AGI’s arrival is imminent - to whether a straight shot to ASI (artificial super intelligence) is possible. Ilya Sutskever is one of the most respected minds in AI, worked under Geoffrey Hinton (Godfather of Neural Nets) - and was the first person (if memory serves) to realize that scaling would work (bigger models with more parameters and data would be smarter). Ilya recently raised $1billion from VC Lords like Andreessen Horowitz and Sequoia to build ASI.
As the cost of intelligence drops demand for it goes up. And demand for AGI will effectively prove to be limitless.
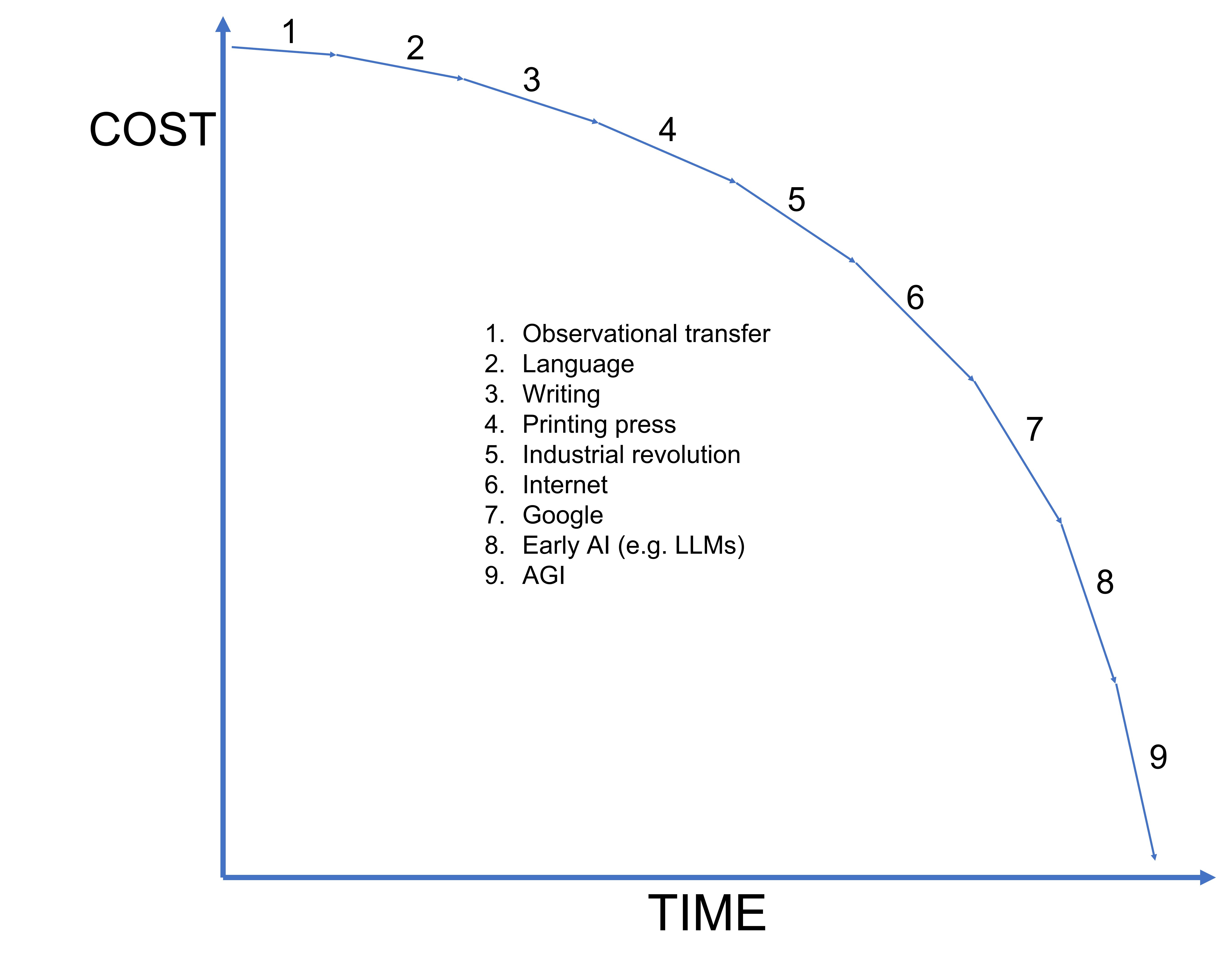
Quick aside - I want to head off criticism that the massive capex we’re seeing means that the cost of intelligence is not heading to zero. A human costs tens of thousands of dollars per year to “run” (at least the ones capable of contributing to science) - AI Agents will cost a small fraction of that per unit and intelligence per unit of cost will increase exponentially. If I wanted to perfect the chart above I’d make the [9] line head asymptotically to zero rather than look like it’s crashing down into it, but the asymptotic slope would start heading to the right very close to zero…
One of the things that annoys me these days on Twitter are the arguments about a good definition for AGI. My definition is simple and the best one I’ve heard: AGI means a computer being able to do anything a remote worker could do. They aren’t there in person, but you can talk to them like a human, they can do anything a human could if the human had no physical body but complete control over a mouse, keyboard, screen, etc. By this definition, my personal current view is that “AGI” will become available to the mass public on desktops in 2-3 years, tablets in 3-4, and mobile phones in 5-6. I agree with the likes of the OpenAI and DeepMind employees that AGI will arrive sooner, but it will take a bit to productize it, safeguard it, plug it in to everything, etc. You will probably be able to interact with the “intelligence” of AGI sooner on mobile devices, but it won’t meet my definition due to latency…
The roadblock to a faster timeline for mobile phones is the hardware required to interact with the “Agent” with zero latency while still being able to access [~infinite memory] and appropriately weigh [context]. Chip design cycles are just too long to crack how to do this on mobile phones for the next few phone generations.
Similarly, human-equivalent AGI would be the same level of intelligence but connected to the body of a humanoid robot.
I’ve written a variety of posts about the implications of “AGI Agents”, notably:



I won’t spend time re-hashing points I’ve already made, except to remind you that once we have Agentic AI - it is only a matter of time before the effective number of humans begins to rise exponentially. At any point in time some number of people are working to solve some problem (for example how to use gene editing to extend human lifespan; how to cure rare illnesses; how to improve battery density; etc). Agentic AI will increase the effective number of people working on these problems by many orders of magnitude - the only limit will be how fast we can construct data centers. And, these humans will keep getting smarter…Remember, one of the first tasks the AGI Agents will be set to is recursive self-improvement…
It’s entirely plausible that by the end of the decade we’ll have hundreds of millions of PhD equivalents working on the world’s toughest problems, and not long thereafter the number will be measured in the billions (hence my title above: 1 billion new people but no more mouths to feed). For reference, here’s a chart of the number of STEM Doctorates awarded each year. The implication is that we’ll go from making 50k new PhDs per year as a species to making millions…
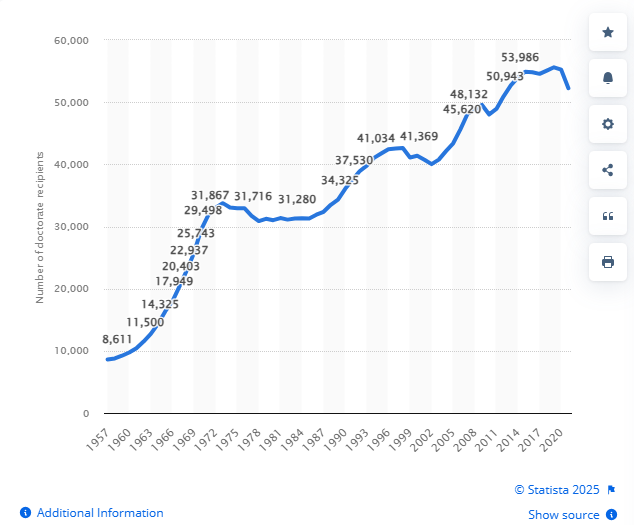
This - in a nutshell - explains why I am so bullish on the future of humanity. Consider the following (this comes from my Twitter profile so may be repeat for some of you, sorry!)…
If you think it is going to take humanity 50 years to figure something out (a cure for cancer, AGI, etc) - we might be just 11 years away. Before I walk through the math here are a few points worth noting:
1. Some types of compute efficiency (alternatively: the cost of intelligence) are improving by 50%+ per year.
2. Efficiency in analyzing biotech lab samples has improved by around 40% per year over the past 20 years (we can now test millions of samples with the same amount of human resources that were once capable of handling thousands).
3. However many people you think are working on a problem - the number is likely to be at least 10X higher. Why? Because most people working on compute efficiency, AI, robotics, etc are at least tangentially working on that problem. For example, no one would have thought about Nvidia as a "natural language processing company" a few years ago, but we now know that their GPUs are what unlocked ChatGPT. A similar argument will soon be made regarding their Chips' impact on biotech (as Jensen so regularly reminds us).
This is the beauty of general purpose technologies (I talk about this dynamic in detail in my “Agents are coming” post) and the MEGA trend of everything turning into an engineering problem.
Now for the math. Let's be a tad more conservative than the above numbers imply might be possible and assume that we're accelerating the rate at which we're solving a problem by 30% per year. Put differently:
From 2024 to 2025 we make one year worth of progress. From 2025 to 2026 we make 1.3 years worth of progress (30% more).
From 2026 to 2027 we make 1.69 years worth of progress (30% more than from 2025 to 2026).
The numbers blow up pretty quickly: By year 7 we will have made more than 17 years worth of progress, and by year 10 we will make 10 years worth of progress in a single year, and will have made 42+ years worth of cumulative progress.
Most people need to dramatically shrink the timelines over which they expect the seemingly impossible to turn into the imminently probable.

Mind you - the above scaling is at a rate of 30% - whereas we’re seeing rates of 2-10X in AI right now in terms of price performance (100% to 1000%).
I want to make a quick aside before getting back to the post. One of the reasons people are so bad at predicting the future is because they don’t account for changes in the way we do things. For example…
People are always criticizing my view that Aging will be cured by the late 2030s.
“We don’t even have the first treatment yet…”
“Phase I / II / III trials take YEARS to run…”
“We can’t even make mice live longer except by starving them!”
The reason we have Phase I/II/III trials is that we don’t have accurate simulations of the body/diseases/cells. What do we need to accurately simulate the aforementioned? Shittons more compute + higher resolution body-scanning + a way to observe cells at-scale and in real-time. Once we have simulated everything - what people call “creating digital twins” - timelines for testing new chemicals will drop from years to minutes…I don’t know when this will happen - but once it does everything changes overnight…
Another point people make is that much of lab work is necessarily done by humans and involves physical labor. Someone has to physically transport a chemical from this place to that, put it from a tube to a petri dish, etc...Again, my response is that much of this will be automated with intelligent (embodied) machines (humanoid robots, most likely).
The future is coming faster than everyone thinks…
#2 We could be looking at a situation where demand for data centers exceeds our ability to construct them straight from now through the singularity.
To summarize our learnings from point 1 and add a few more takeaways:
Daddy Satya believes AGI is imminent - as evidenced by his capex - so does the rest of Big Tech…
Expect all of Big Tech to increase their Capex guides…
Intelligence will be extremely useful b/c all problems can be solved by it…
The Agents are coming…
I spent over 6 hours having a conversation with Claude about related topics: growth of semiconductor demand, implications of Agents on data center growth, energy bottlenecks (and more). That conversation is linked here on my 8wolvespilgrimage Substack (something new I created to post ramblings that I didn’t think were worth sharing on 01Core). If any of you haven’t played with Claude or ChatGPT you will probably be stunned that such a conversation is possible. While there are obvious errors in some of the things it states the conversation as a whole provided lots of useful and accurate information.
The main takeaway from my most recent research into “Agents” is that they will require enormous amounts of memory. Why? Because Agents can’t always be sifting through the sum total of human information to address whatever problem they’re currently focusing on. That searching process is too compute intense and makes real-time interactions impossible. Here’s an example.
I want to have a conversation with my personal Agent about a TV show I just watched. This Agent “knows” everything about me, including what I enjoy watching, which characters are my favorite, what food I like, what I do for work, etc. The Agent needs to have contextual understanding not just of the TV show, but of everything else that I’ve run into over the past few months (e.g. the information that will be at the forefront of my brain). What if I wanted to incorporate a lesson from the TV show into a business presentation - for example - and I wanted the Agent to help me think through how best to do that?
In order for the Agent to interact with me with zero latency (as a human effectively does) - it will need to have a separate repository of all relevant information (basically anything that is likely to be stored in my meat-brain memory + anything I am likely to query it about) - including the data from the TV show I watched. The implications of this are staggering…
Today the video on YouTube is stored by Google. The things I’ve watched on Netflix are stored by Netflix, and so on. The information I’ve read is stored by the hosts of that information (e.g. Substack, Twitter, email providers, etc). However - in the future the Agent will need to be storing an extra copy of ALL of this information b/c the search space and weightings to incorporate this information into a latency-free conversation with me are too vast and too complicated to process in real-time. My Agent will need not only its own “cloud” that caches any data that my brain is likely to possess, but also that stores the data I am most likely to be interacting with at any given moment on-device (an extremely dynamic and complicated process no one has figured out yet). You think Amazon predicting what products to store in what distributions centers to make same day delivery possible is complicated? Try predicting what information will be needed on-device to chat with a meat-brain with zero latency and perfect context…
Today the amount of data processed is around 100X the amount of data created each year. For example, each time someone watches a YouTube video that data is processed - which could be millions of times - but that data was only created once…Imagine how much more processing we are going to need when Agents are constantly adjusting what they keep in cache to interact with us…
The takeaway is this: while we are building out the “intelligence” piece (Nvidia GPUs mostly today - a build-out that will continue going straight through the singularity- though I’m sure with ups and downs) - we can also infer that there will be an explosion in demand for memory. Collectively - the demand for intelligence and memory could put humans in a position where we can’t build data centers fast enough to satisfy the demand for AI for many years…
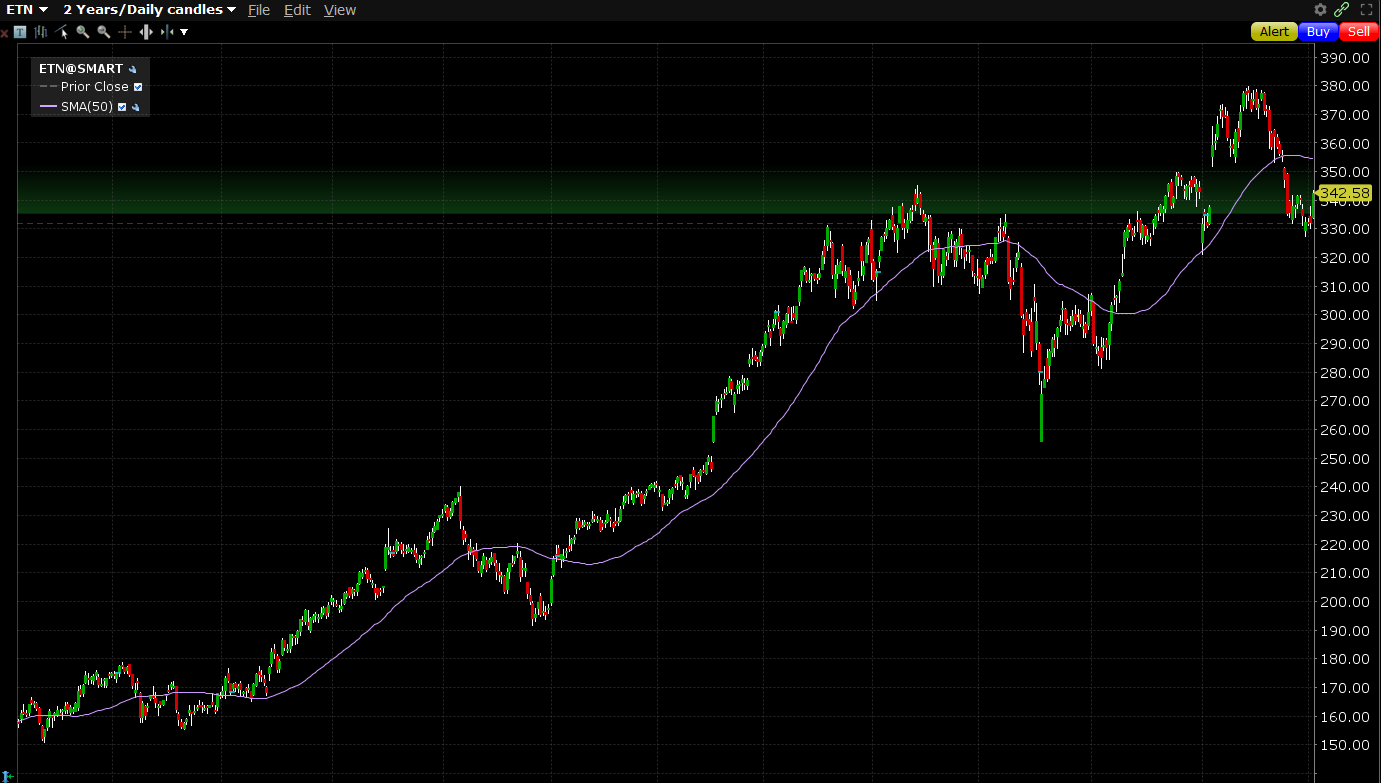
Bottlenecks are: the physical infrastructure, transformers, electrical contractors, permitting, and energy generation. These things can only be scaled so fast. Worth noting, this is an extremely attractive situation for companies like Eaton to be in. It can be nerve wracking to rapidly scale capacity if you don’t know whether the demand will end up being a temporary surge. Eaton executives are positively giddy on their earnings calls lately because they (correctly) believe this is a new decade-long mega trend. See their stock chart below:
Dell’Oro Group forecasts that 2024 will see data center capex up by 35% vs. 2023, and that it will CAGR at a 24% through 2028. I think this is reasonable and want to make some additional comments. For reference:

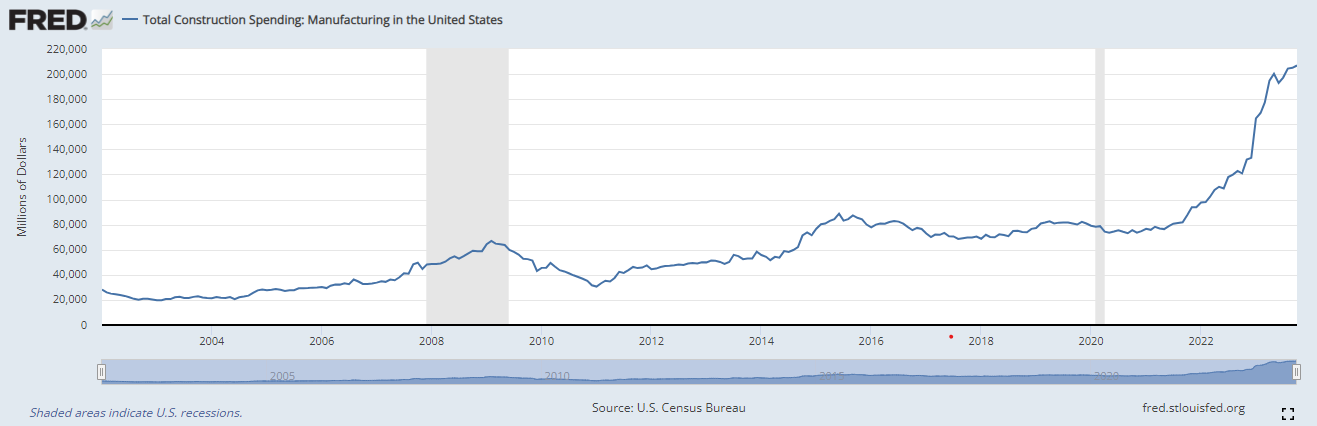
$400 Billion being spent on anything but war or entitlements is unprecedented in history even after adjusting for inflation - even moreso when considering that the spenders are not state supported. The only exception that comes to mind are multi-year infrastructure projects. For example, the US highway system was built over 35 years and cost just north of $630 Billion in today’s dollars. This $400 Billion is being spent in a single year… This amount of spending also dwarfs historical levels of investments in the United States. This chart comes from the Federal Reserve branch in St. Louis - the data source is the U.S. Census Bureau. It shows that construction spending on manufacturing has increased from approximately $80B per year in 2020 to $200 as of the end of 202. These figures are not adjusted for inflation, but even using constant dollar terms it is still more than a double.
This chart comes from the Federal Reserve branch in St. Louis - the data source is the U.S. Census Bureau. It shows that construction spending on manufacturing has increased from approximately $80B per year in 2020 to $200B as of the end of 2022. These figures are not adjusted for inflation, but even using constant dollar terms it is still more than a double. Note that construction spending does not include (I’m assuming) the cost of things like GPUs and Memory - which comprise 50%+ of the total cost of a data center. Mind you Microsoft is going to spend $80B on data centers next year - of which tens of billions will be on constructing the shells and building out electrical/energy infrastructure - and they’re just one company…
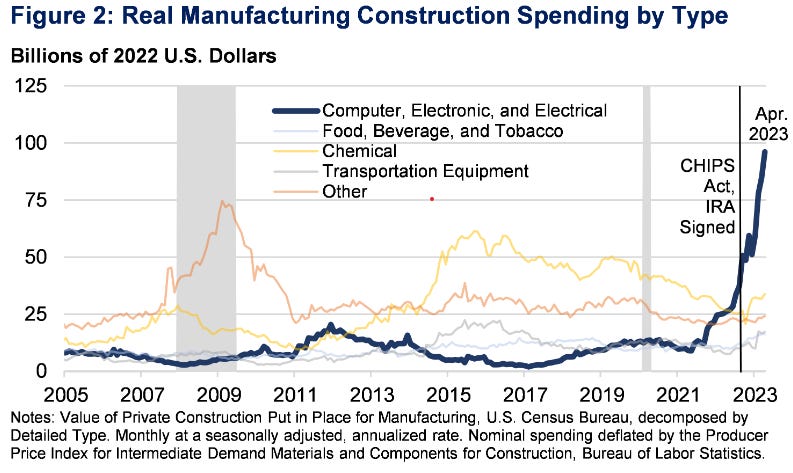
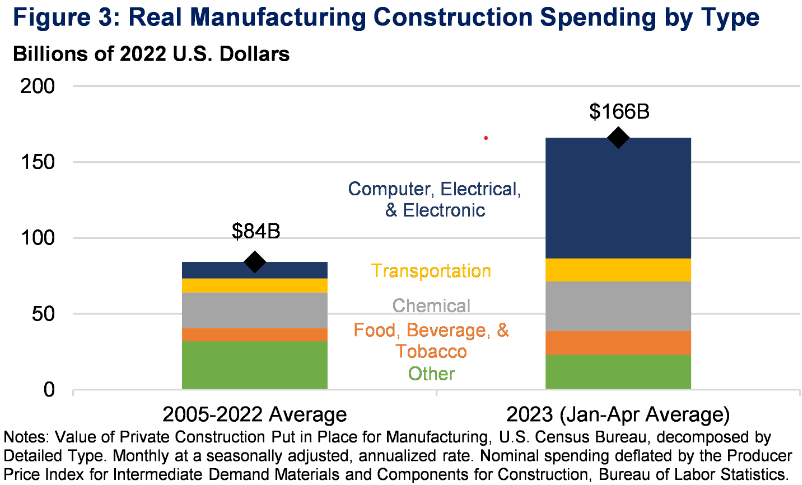
The next two charts break down construction spending by category.
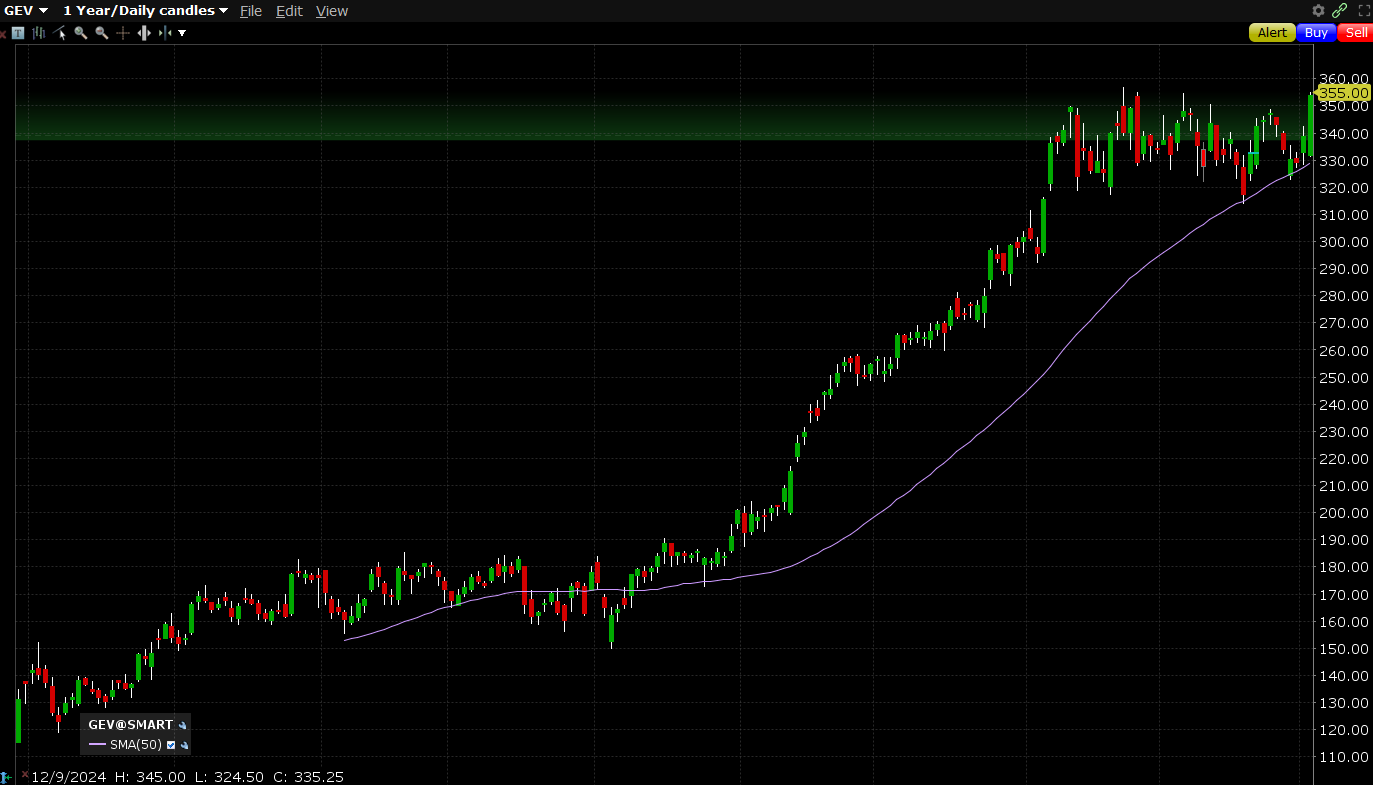
This build-out has seen some wild moves in other companies related to infrastructure, GE Vernova being the best example. It’s stock is up 3X in the past year even though its margins are still dog-shit and locked in for the next 2 years (I’m sure they’ll start raising pricing for future projects given the size of their backlog).
Eaton started tracking something they call “Mega Projects” - which if memory serves are billion dollar + infrastructure buildouts (e.g. new energy plants, new data centers, etc). The growth of mega project announcements has been staggering, and Microsoft’s recent $80B announcement will just add fuel to the fire:

We are literally witnessing the birth of intelligent machines in real-time. I’ll close by re-iterating a point I’ve made in numerous other articles…
The most obvious beneficiaries of the proliferation of AI generally and Agents specifically are: 1) companies that own operating systems (Apple, Google, Microsoft and sort-of Meta given the size of its properties and uniqueness of What’sApp); the entire semiconductor complex (as a basket, particularly semicap); and cloud providers (Microsoft, Google, Amazon).
There are literally thousands of startups working on Agents today, however - my belief is that while a few hyper-niche Agent startups will survive - the killer application that will create trillions in market cap value is general agents. Agents that know everything about us - whether business or personal. General agents can ONLY be provided by companies that own operating systems because only the OS owner will have access to all data from all apps (email, Netflix, calendar, text messages, etc).
As always, the safest thing to do is buy the basket - this rising tide will lift all boats - and neither semiconductors nor Big Tech is expensive if you aggregate them all and create pass-through financial statements (e.g. treat them as a single company) relative to their growth. Further, the odds of any of these companies being disrupted by upstarts is near zero. The capex requirements are too large, the value of distribution and data collection at scale too high. IF a member of the basket is disrupted it will be BY another member of the basket - but the economic profit will nonetheless remain inside the basket.
Hope everyone has a wonderful 2025 - get optimistic!