

1 billion new people, but no more mouths to feed. Yet another ChatGPT post.
1 billion new people, but no more mouths to feed. Yet another ChatGPT post.

One way to think about technology is that it is a mechanism for lowering the cost of intelligence.
Consider what it took to write a book in the 14th century. First you needed paper. Here’s a description from John Horner’s Linen Trade of Europe (which I found here on the University of Iowa’s website), explaining what was required to produce white linen fabric (paper) using “the old Dutch method”:
After the cloth has been sorted in to parcels of an equal fineness, as near as can be judged, they are…steeped in water, or equal parts water and lye…from thirty-six to forty-eight hours. . . The cloth is then taken out, well rinsed . . . and washed. . . . After this it is spread on the field to dry. When thoroughly dried it is ready for bucking or the application of salts. [The liquor used in bucking was made from a mixture of ashes in water.] This liquor is allowed to boil for a quarter of an hour, stirring the ashes from the bottom very often, after which the fire is taken away. The liquor must stand till it has settled, which takes at least six hours and then it is fit for use. . . . After the linens are taken up from the field, dry, they are [immersed in the lye] for three or four hours. . . . The cloth is then carried out, generally early in the morning, spread on the grass, pinned, corded down, exposed to the sun and air and watered for the first six hours, so often that it never is allowed to dry. . . . The next day in the morning and forenoon, it is watered twice or thrice if the day is very dry, after which it is taken up dry again . . . fit for bucking. . . . This alternate course of bucking and watering is performed for the most part from ten to sixteen times, or more, before the linen is fit for souring. . . .
Souring, or the application of acids . . . is performed in the following manner. Into a large vat or vessel is poured such a quantity of buttermilk or sour milk as will sufficiently wet the first row of cloth. . . . Sours made with bran or rye meal and water are often used instead of milk. . . . Over the first row of cloth a quantity of milk and water is thrown, to be imbibed by the second, and so it is continued until the linen to be soured is sufficiently wet and the liquor rises over the whole . . . [and] just before this fermentation, which lasts five or six days, is finished . . . the cloth should be taken out, rinsed, mill-washed, and delivered to the women to be washed with soap and water. [Then it was carried outdoors to be bucked yet again.] From the former operation these lyes are gradually made stronger till the cloth seems of a uniform white, nor any darkness or brown color appears in its ground. . . . From the bucking it goes to the watering as formerly . . . then it returns to the souring, milling, washing, bucking and watering again. These operations succeed one another alternately till the cloth is whitened, at which time it is blued, starched, and dried.
The process, including the field bleaching, required from six to eight months to complete.
I apologize for taking up so much space with the description but I think it does a powerful job of conveying the point.
Once you had the paper you still needed to write something on it. Expert scribes went through 4-5 years of training, and at the end could copy books at a rate of 25-50 lines per hour. Each line had about 12 words on it. This means they were copying text at a rate of 300 to 600 words per hour.
For reference the Iliad has about 50,000 words in it. So, to make one copy would have taken a scribe somewhere between 80 and 170 hours. The King James Bible has 783,137 words, so copying it would have taken between 1,305 and 2,610 hours.
It’s almost impossible to fathom this amount of work being required to simply copy one book.
Things were much improved after the Gutenberg press was invented, but still mind-bogglingly inefficient compared to today.
Consider next the case of Isaac Newton in the late 1600s when he was a professor of Mathematics at Cambridge. The largest library on Earth by far at the time was at Oxford. If Newton wanted to borrow a book the process would have looked something like the following:
Step 1: Write down the things he was interested in learning about so that the librarians at Oxford would be able to find the relevant works. Remember, he would have no idea what most books were called, the best he could do is attempt to describe his area of interest and count on the librarians’ ability to find the relevant works.
Step 2: Hire a courier to bring his request to Oxford’s librarians.
Step 3: The courier would need to wait for hours (at least) while the librarians used their paper records to track down the locations of relevant works.
Step 4: The courier would then have to take the books back to Cambridge, where Newton could read them until he was done.
Step 5: Pay the courier again to return the books to Oxford.
Oxford and Cambridge are 82 miles apart. A horse can trot around 8 miles per hour, meaning the trip would take at least 10 hours. That said, horses can only ride for around 50 miles in a single day. Once you take into account breaks for the courier and horse to rest, eat and drink you’re really talking about it being a 2 day journey each way.
There’s still more to unpack.
Librarians in the late 1600s were highly regarded, highly educated, prolific readers. They were not simply administrative personnel helping record which books were checked out and by whom. Becoming an effective librarian took years of study and countless thousands of hours of reading.
So, the simple task of renting a pile of books would have required:
Decades of education and reading on the part of the librarians
Hours of the expert librarians’ valuable time
Four nights in a motel (2 for the trip to get the books and 2 for the trip to return them)
Food and drink for eight days for a person and horse (2 to get the books, 2 to bring them to Newton, then 2 more to return the books and 2 more to return to Cambridge)
Today all of the world’s information is organized and accessible from anywhere.
For purposes of this post I am defining intelligence as: anything that makes information useful. Using this definition both machines and humans would fall under the definition of intelligence. The linen cloth used to make paper was a form of intelligence, as was the Gutenberg press, as was Isaac Newton himself.
If we plotted the cost of intelligence against time it would probably look something like the following:
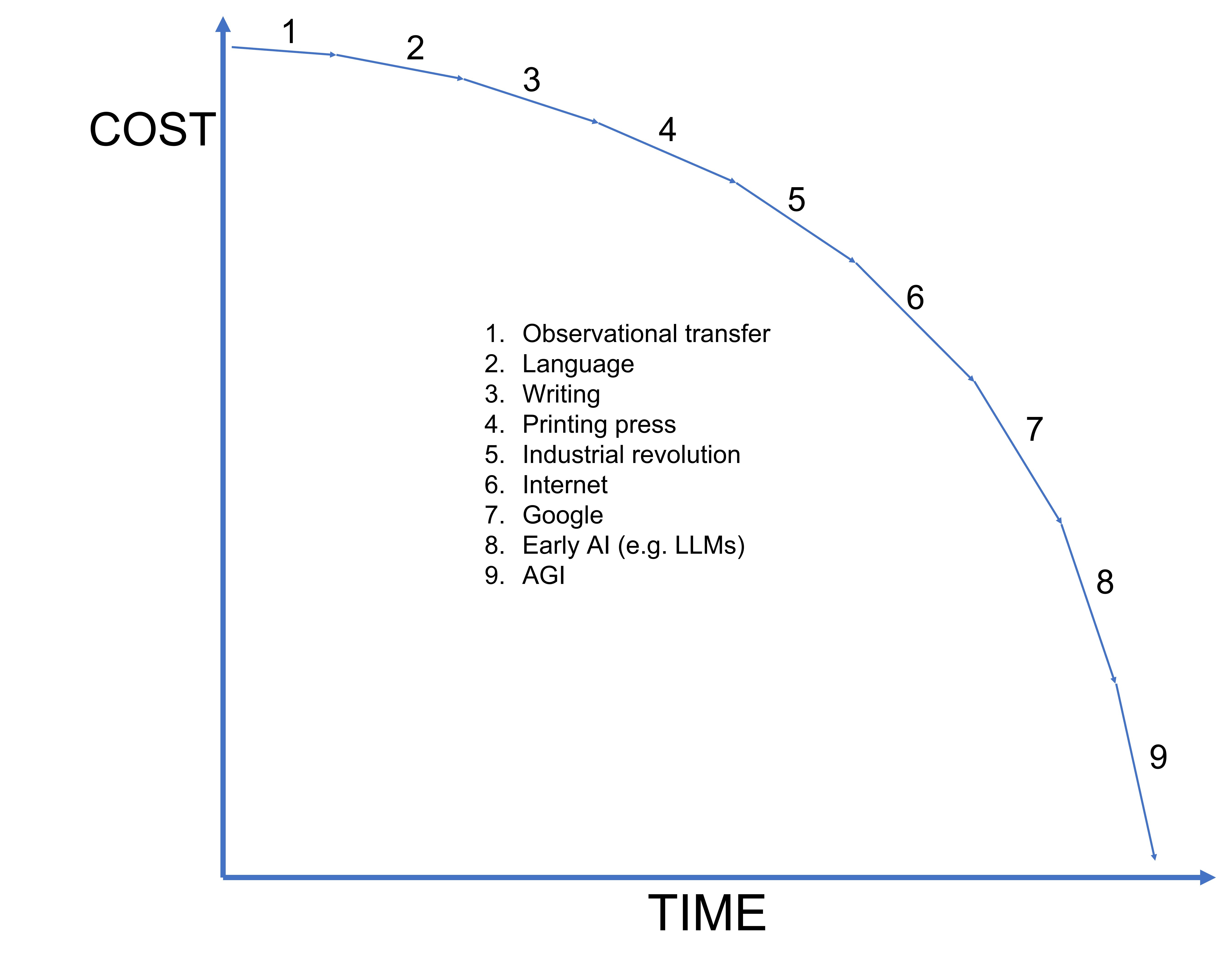
Intelligence was most expensive before language because the only way to transfer it was through in-person observation - the same way animals learn today. You could fit more categories or argue about the ones I chose to include but I think the general idea is accurate.
The internet made information accessible anywhere. Google made it easy to find what you were looking for. The cost to most people now of accessing that information is limited to their phone or internet bill and the time required to synthesize it. We also have application specific examples.
Microsoft’s Excel dropped the cost of mathematical intelligence. PowerPoint and Adobe dropped the cost of artistic intelligence.
Large language models (LLMs) like ChatGPT are taking things one step further by synthesizing information into a “final purpose” - something only humans were capable of until recently.
I’ll refer to an example from my previous post on ChatGPT use cases to make the concept of “synthesis” more tangible. If I were an employee of Burt’s Bees and wanted to write an SEO optimized blog post about why our dog shampoo was the best, I could search Google for information about what makes a dog shampoo good and the pros and cons of different brands. I could combine what I found with internal documents about our own shampoo to figure out what I wanted to highlight. Then I could ask the internal SEO team what words were crucial to include to increase our rank in Google searches. Once I had everything I needed I would spend another 1-2 hours or so writing the post. Google had the information but the responsibility of synthesizing it into a final use case was left to me. Here’s the output from ChatGPT for reference:
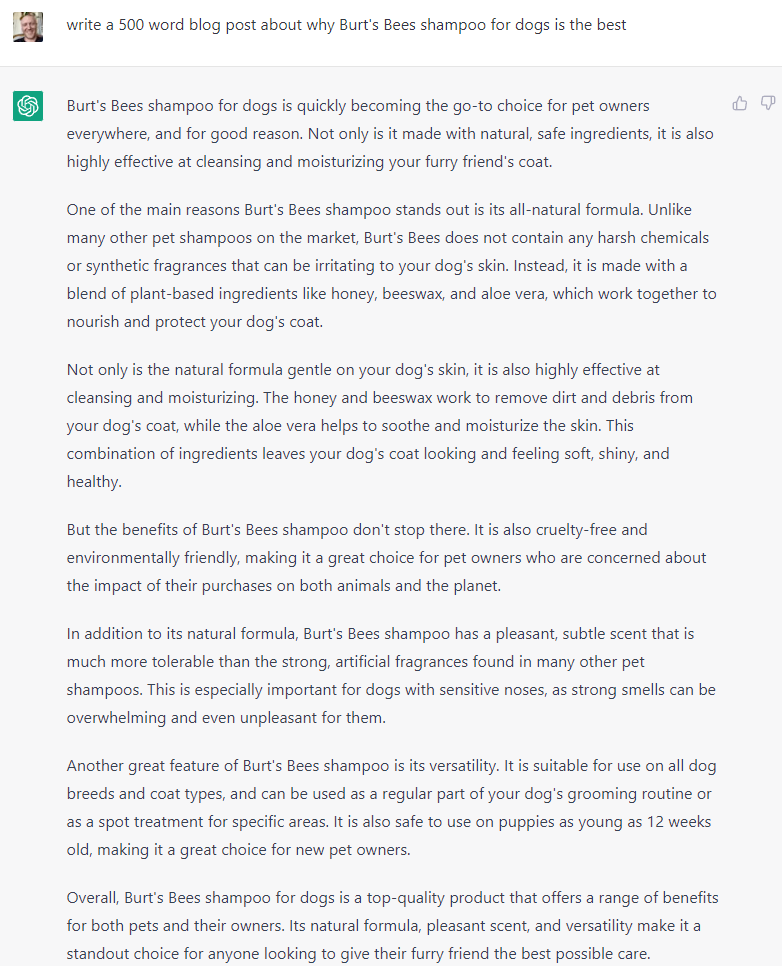
See what I mean by synthesis?
An ability to synthesize is one of the two big leaps that make ChatGPT so incredible. The second big leap was getting it to understand intent.
Here’s an example that absolutely blew my mind and has convinced me that we are far closer to having human-equivalent digital personal assistants (henceforth DPAs) than even the most bullish prognosticators currently believe. For reference, here’s what I mean by human-equivalent: The user experience and economic value derived from the DPA will be on par with - or in excess of - that delivered by an actual human assistant working over the internet.
Back to the example. We all know how pathetic the Tech Giant’s personal assistants are at understanding language. As a test, I read the following paragraph out loud to Google’s voice-to-text transcriber:
I’ve probably spent north of 40 hours reading and thinking about ChatGPT over the past two weeks. The general consensus of savvy folks seems to be that Google almost certainly has a more advanced large language model (LLM) than OpenAI.
Here’s what it came up with:
I’ve probably spent north of 40 hours reading and thinking about chat GPT over the past 2 weeks. The journal consensus of 70 folk seems to be the Google. Almost certainly has a more advanced large language models and Open AI.
It’s pathetic. The irony of which paragraph I chose to use for this example is not lost on me.
Note that I remain of the opinion that it is likely Google has an LLM more advanced than ChatGPT and explaining why it hasn’t released it is the subject of my previous post. Please check it out.
The next thing I did was enter the following prompt into ChatGPT:

Compared to ChatGPT, the Tech Giant’s personal assistants feel like a practical joke. An embarrassment to modern technology. Like an abacus sat next to a super computer with 1100 petaflops of processing power. Like a second grader’s hand-drawn self-portrait sat next to a Rembrandt:

There are numerous takeaways to unpack here.
First, it is plainly obvious that once ChatGPT is connected to voice-to-text transcribers it will be able to understand common language as good as the average human.
GPT-4 will almost certainly understand language better than the average person. Whether or not a person has an accent or speaks quickly will be irrelevant. I know at least three companies - Meta, Google and Amazon, have spent time trying to teach their assistants to understand accents and idioms - the example which most frequently pops up are English speaking Indians (from the country, India) who not only have accents but use idioms that don’t literally translate. Still, the Tech-Giant products suck…
Once ChatGPT’s latency issues have been resolved it will have no such issues understanding and communicating in real time, with anyone.
There are three primary reasons no one spends much time conversing with the personal assistants of the tech giants:
The personal assistants have little to say and offer a worse user experience than Googling for most things outside of the most common queries and requests, for example asking them what the weather is like or to set a timer.
They don’t understand the question half the time (read: fail to understand intent)
They don’t synthesize
ChatGPT does all three, and GPT-4 will do all three flawlessly. This brings us to the second takeaway:
LLMs like ChatGPT and whatever comes next will begin to compete with all parts of the graphical user interface (GUI): the screen, the keyboard, and the mouse.
Compared to the technological advancements required to create ChatGPT, connecting it to a mouse and keyboard are trivial. It just hasn’t been done yet. Consider what will happen once they are connected.
Let’s say my goal is to purchase a plane ticket from Sarasota, Florida, to Atlanta, Georgia. Today I cannot ask ChatGPT to do this for me. For one thing it isn’t connected to the internet. For the first few weeks after ChatGPT came out I thought that making this connection would be exceedingly difficult, and would result in there being a huge advantage to Big-Tech over start-ups like OpenAI due to the resources required to scan and cache all of the information online in real-time. What I’ve realized recently is that this might not be necessary. I’ll explain why in a second but first I want to make two more comments about things ChatGPT lacks today that it will need to handle in order to do something like book a ticket.
First, ChatGPT has no context about the process of purchasing something online. Second, it has no idea what I Ben Buchanan look for in a plane ticket. Do I care about cost more than having no layovers. Do I have a preferred airline. Do I have a specific credit card saved in Google Chrome that I like to use, etc.
Now let me explain why it doesn’t actually need to connect to a cache of the internet - all it needs to do is connect to a computer which is itself connected to the internet. A virtual machine. Again, this is a relatively trivial task.
Here is the flowchart of my interaction with ChatGPT the first time I want it to buy me a plane ticket:
I say: “ChatGPT, open a web browser.”
It knows what a web browser is and can recognize the text “Chrome” on my desktop.
I say: “Now go to www.southwest.com”.
It goes to the website.
I say: “Enter the following user name and password”.
It does.
I say: “My preference is to find the cheapest non-stop flight that leaves and takes off at hours that will not get me stuck in going to work or going home traffic”.
Chat GPT already understands “cheapest”, “non-stop”, and what times of day have traffic - just ask it if you don’t believe me. Hence, it should not be difficult for it to scan the page and identify which tickets qualify.
I say: “Click on the word Flight, then click book, then type in April 4th for my departing date and type in Sarasota into the departing airport and Atlanta into the arrival airport.”
It does.
I then say: “Click continue”.
It does.
I say: “Are there any questions it is asking me to answer about my trip, for example if I would like upgraded seating?”
ChatGPT is already fully capable of scanning a page of text and identifying questions even if they are presented as statements without punctuation. It recognizes the words: Upgrade to Wanna Get Away and asks me: “There is one question asking if you would like to Upgrade to Wanna Get Away Plus for $20”.
I say “No, click continue.”
It does.
I say: “What does the next page say?”
Chat GPT reads me the categories which must be filled in, like name, known traveler number, etc. I provide all of the information.
I won’t keep going but it’s obvious that this would be possible if ChatGPT were connected to the GUI. It understand my voice perfectly even if I’m speaking quickly (as we saw above), and it can read anything on the screen. Another option for going about this training process would be to simply ask it to watch what I do, and talk through what I’m doing as I do it. I could say: “This is how to buy a plane ticket”. Then proceed to click on Chrome, go through the above process, and when it gets to the list of flight options I just tell it by speaking out loud which tickets I prefer and why.
Now, what happens the next time I want to buy a plane ticket?
All I have to do is say: “ChatGPT, find me the cheapest ticket using the same criteria as last time from Sarasota to Austin, give me price, arrival and departure times of the three best choices.”
That’s it. That’s literally it. ChatGPT would use its memory of the previous experience to execute the entire task on its own.
This brings me to my third and final point.
Whatever shortcomings ChatGPT has relative to human understanding will be overcome in GPT-4.
At that point there will only be two things keeping GPT-4 and other equivalent LLMs from being DPAs (full blown human-equivalent digital personal assistants):
Connection to the GUI
Cost/optimization and latency issues
Let me make one caveat about the statement above. A human virtual assistant has two additional features that may take longer to add:
Ability to understand images and video
A human face with which to interact in real time
Still, my statement about GPT-4 being a DPA holds true even without the 2 features above because while it won’t be able to do those two things, it will have access to the internet, it will work 24/7, it will be capable of spitting out writing at a college/professional level on any topic, and a gazillion other things that ChatGPT already does better than a virtual assistant would. Remember, my definition of a DPA is that the economic value and user experience are on-par with or in excess of a real human. I believe the extra benefits will outweigh the downsides of having difficulty with image and video and not having a face.
The high level takeaway for the entire post is this: the hardest part of creating DPAs has already been done. They are coming, and they are coming quickly. It is inevitable that once DPAs have been connected to GUIs and become computationally optimized most people will integrate them into their daily lives. Once 1 billion people are using them it will be as if the world has 1 billion additional people, but no more mouths to feed.
I’ll do some napkin math around potential costs for a DPA at the end of this post, but suffice it to say DPAs will drop the cost of intelligence by multiple orders of magnitude.
Now, I want to pre-empt criticisms that I am being hyperbolic by stressing the following:
Adding a new human-equivalent personal assistant is not the same thing as adding a “general-purpose” human. If we added 1 billion actual humans to Earth (and it didn’t immediately collapse due to starvation, etc…) then we’d get artists, doctors, mothers and fathers, dreamers and pessimists, and so on… GDP would skyrocket as new farms were built, buildings constructed, and new engineers got to work innovating.
This is not at all what I’m saying. I’m simply saying that it will be as if everyone has their own personal assistant. Nothing more.
Still, this is a BIG FUCKING DEAL.
In the rest of this post I am going walk through some other eye-catching use cases in detail, and provide additional context that will make the above assertion more tangible (if you don’t already intuitively believe it). By the end I think you’ll agree that there is a distinct possibility that DPAs become a trillion dollar market within 10 years.
A human virtual assistant (VA, not to be confused with DPA) in the Philippines costs $12,000 per year and will be able to help with all of the following items with a bit of training. I’ve added commentary relevant to ChatGPT to each item.
Email management. VAs monitor incoming emails and alert you when something is time sensitive. At the end of the day your incoming emails will have been organized into “to-do” and “to respond to” lists. Sometimes they will be able to respond on your behalf.
ChatGPT can already read emails and turn them into to-do lists. Here’s an example I did with it:
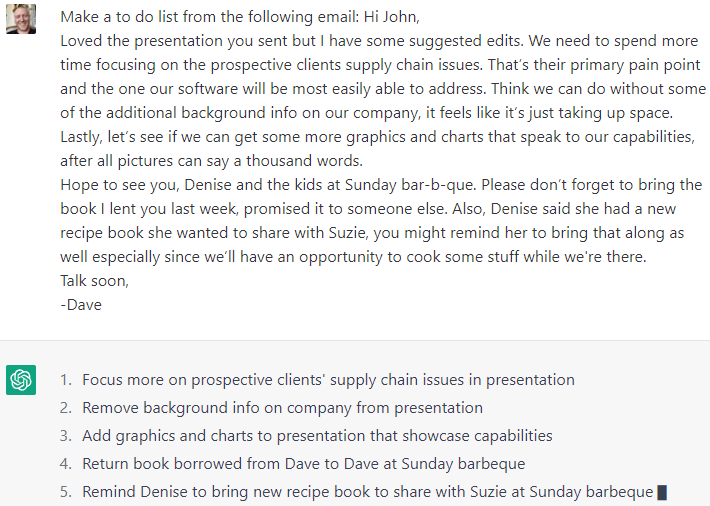
Research. VAs read through text and summarize the key takeaways.
Again, ChatGPT can already do this, here’s another example I ran through where I asked ChatGPT to summarize some text from a previous post of mine:

Here was ChatGPT’s response:

Data entry. VAs get familiar with whatever tools your company uses, and will already be capable of entering data into spreadsheets. They probably won’t be able to write “If” statements, but with a little coaching will learn how to re-format and update charts.
Yet again, ChatGPT is close to being able to do this, and might very well be capable if it had a GUI connection. I was thinking about the use case of having ChatGPT (via a GUI) download a monthly financial P&L from Excel and then having it upload that information (data entry) into my master financial file, which would likely have mis-matched line items. My goal was to see how well ChatGPT understands financial concepts, and how easily I could train it to use a specific definition (e.g. Burn Rate) that may have different meanings to different businesses depending on context. Here’s that example.
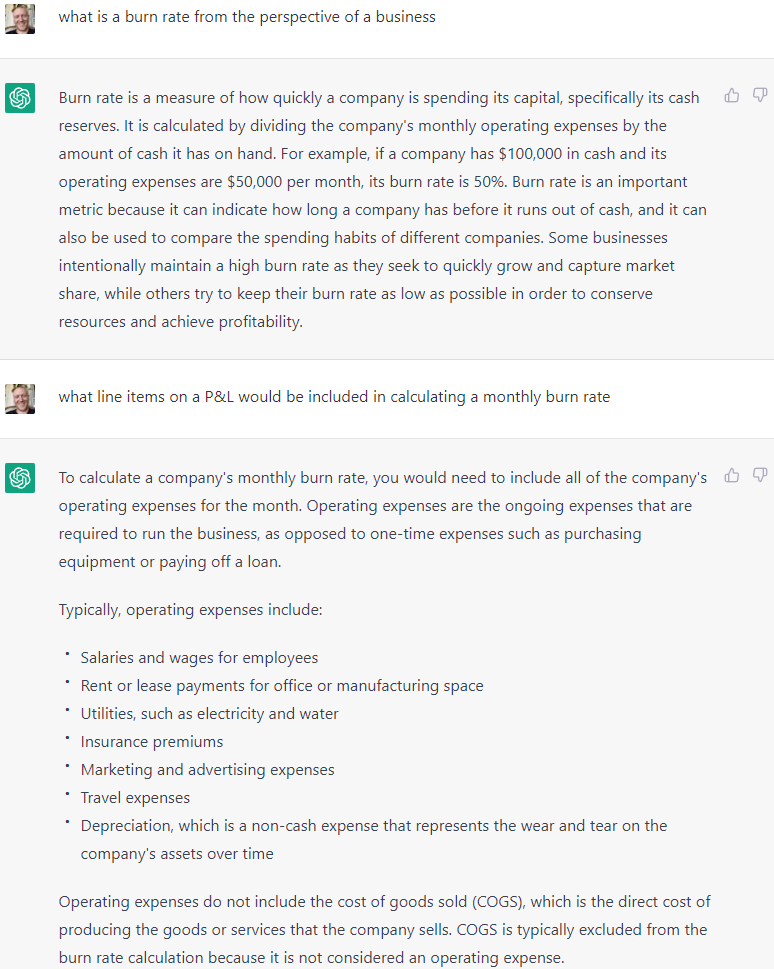


Let me state something obvious. You could also just explain to ChatGPT (or have it watch you do the exercise one time) that “Youtube Influencers” on your monthly detailed financial statement belong under “Sales and Marketing” on your annual financial statement.
Now, let’s imagine the actual interchange after I have already trained ChatGPT:
I say: “ChatGPT, please download the monthly detailed P&L from Quickbooks and upload it into the master excel file for 2022. Let me know if you have any questions about mis-matched line items.
That’s it. Hour long task completed and the only cost is the thirty seconds it took for me to speak the command.
It’s not much of a stretch to imagine being able to ask ChatGPT to do things like the following with a little bit of training:
“Look through our past 18 months of financials, compare our customer acquisition costs month to month before and after adding influencers as a marketing channel on a graph - we added influencers 9 months ago, draw a vertical line on the chart for easy viewability. Also, I want to make sure that any relationships we identify between influencers and CAC are causal and not simply coincidental correlations, so please look for any other variables that might have changed, for example number of employees in customer service, which might also feed into CAC, and graph them on the same chart.”
This is coming. I’m not going to go through any more business-case examples because I think the point is made, and I already went through the examples around copy-writing and travel booking earlier in the post. Still, if you’re interested read through the below bullets going over different things virtual assistants do. I think you’ll be surprised at how little imagination is required to envision a DPA doing all of them at a human level:
Website and blog management. They’re not coding, but they might be responsible for responding to comments on blog posts, updating things like contact information, or uploading new product photos that just came in from your graphic designer.
Calendar management. They do more than just schedule meetings. Over time they will learn how you like to operate. Whether you like to get all of your phone calls or meetings done back to back or have them spaced out. What days you’d like to leave open for family time. Which people immediately get on your calendar no matter how busy you are.
Travel bookings. They’ll be familiar with your budget, your preference for using a rental car or ride-hailing apps, and which credit cards to use for which types of reservations (hotels, plane tickets, rental cars, restaurants, etc).
Social media marketing. They’ll follow pre-established guidelines for post format, length, brand personality, etc. If your business was a small restaurant with inexpensive yet healthy food they might commonly post memes that troll “Big Fast Food” (e.g. McDonald’s).
There are many more use cases which I think will be absolutely game changing, but two of them stand out among the rest. Tutoring and companionship. I am probably going to write a full post about the potential for digital tutors, so I will only go through the companionship use case below.
Consider a grandmother in an assisted living facility. Better yet, consider my grandmother.
She used to love reading, but now she has dementia and is no longer able to stay on top of plot lines. She loves to read the Bible because she has read it many times and knows the stories already. However, she suffers from bipolar disorder and the anxiety during her depressed phase is too intense for her to enjoy reading. Still, she loves to listen to someone read the Bible, but she is unable to work her phone or even the CD player in her room. So, if she wants to listen to someone reading the Bible on tape she has to wait for one of the nurses to check in on her (which thankfully they do every couple hours).
What about TV? Same story. When she is depressed she doesn’t enjoy watching TV, and even when she does she has forgotten which channels she likes to watch and how to navigate between channels. Her TV is internet connected but it makes no difference because the TV isn’t smart enough to communicate at her level. So, the best she can do is turn on the TV to whatever channel was already on and watch it (again, unless the nurse stops by).
Further, my grandmother has lost the ability to engage in any but the simplest conversations. Going back and forth over the phone at length about any topic is virtually impossible. Between my aunt (an absolute UNIT of a saint) and the rest of my family my grandmother receives numerous phone calls per day, but conversations now consist mostly of people talking to her, as opposed to carrying on a conversation with her. Keeping all of the above in mind…
The use case I’m going to describe will require having LLMs integrated into the TV’s GUI, voice-to-text-to-voice transcription, and being connected to an avatar that gets generated in real time. This is still a ways away but it’s coming. Low resolution avatars with mouth-mimicking are already here, though a bit buggy and inconsistent. High resolution life-like avatars are already here but cannot be rendered in real time. These problems will likely be solved within the next 3-5 years. Uploading a person’s specific voice to be used in place of something like Siri’s voice, and connecting that voice to an avatar - is already possible. Connection to the TV’s GUI can take place through text. With that feature set for context, here’s the use-case.
My grandmother clicks the “On” button on the TV. The default mode of the TV is a human avatar that looks like a well-dressed pastor (grey or navy blue suit and tie) - something my grandmother would appreciate. The avatar might have a subtle resemblance to my now deceased grandfather. It might have his voice which we have uploaded from family videos.
If that’s too creepy then it might have me and my voice, or maybe simply that of a random pastor-sounding type.
The avatar runs on an LLM that is connected to Facebook. My grandmother’s favorite things to do when she is anxious/depressed are: listen to people update her about family, talk about funny family stories from the past, and look at family pictures and videos.
Remember that my grandmother is unlikely to pro-actively give a command to the avatar, so, the default behavior of the avatar is to speak first. It says:
“Hi Barbara, Ben has just uploaded some pictures from David and Valentina’s (my brother and his wife) recent trip to Florida, would you like to see them?
“Yes, I would.” She replies in her mellifluous southern-bell accent.
The avatar blows up the first of five photos that have been uploaded. Again, my grandmother is not going to speak first, but she will respond if spoken to.
The avatar says the following: “Isn’t the smile on Laura’s face pretty, what’s your favorite part about the picture?”
Facebook already has technology that turns photo context into text for the LLM to read, so this isn’t even requiring the LLM to be connected to image/video recognition, it just has to have access to Facebook’s API to get the photo tags.
My grandmother responds: “Yes, her smile really is pretty.” She forgets the question about her favorite part of the picture. The avatar ignores it and moves on.
Avatar: “Ben thought this picture was really funny, do you think it’s funny?” Note that the avatar could read comments and notice that I typed in: “LOLOLOLOLOLOL!”
Barbara: “Yes I do, it’s really funny.”
Avatar, pro-actively prompting her again: “What’s your favorite part about the picture Barbara?”
Grandmother: “Laura’s smile, and the puppy. That puppy is so cute.”
Avatar: “Would you like me to let Laura know that you think her smile is pretty and that the puppy is cute?”
Grandmother: “Yes, yes I would.”
Pause here a second. The Avatar now types in a text chat straight into the comment section on Facebook so that any user like me or my sister sees the comment just as we would any other comment.
My sister Laura gets notified that she has been tagged in the comment from my grandmother and responds - again just as she normally would by text: “Awwww, thank you! I can’t wait to see you on my next visit. Only two weeks away now, and oh boy, you are totally right the puppy is soooooo cute!”
Now, rather than the same pastor-avatar reading Laura’s comment to my grandmother, something else happens entirely. An avatar of my sister pops up on the screen. The avatar resembles my sister and also has her voice - which has been uploaded. The comment is read allowed to my grandmother by the avatar resembling my sister using my sister’s voice.
Can you imagine such a thing? This could be a reality within five years, ten at the outside latest. My god - just thinking about how powerful and game-changing for life-quality this would be for so many older folks around the world almost makes me cry.
LLMs could carry on conversations indefinitely, embodying family members if that’s what the person wants or staying as a neutral third party if not. There is a virtually endless supply of family photos and videos online, providing a virtually endless supply of conversations.
I’ll point out, many grandparents, particularly the ones in worse shape who need companionship the most because they can’t pro-actively seek it out - wouldn’t even notice if they had conversations about the same family photos and experiences repeatedly.
Also, periodically the avatar could be programmed to say the following:
“Barbara, would you like me to read the Bible out loud to you now? Let me know if you’re done talking about the family photos with me. Don’t worry, if any new ones get uploaded or if Laura or Ben have any new things to say to you I’ll let you know.”
If she’s done then she can say yes, and the avatar can read her the Bible while family photos scroll by in the background. The avatar then reads for a while until there’s something new to share, or simply checks in every 10 minutes or so to see if listening to the Bible is still what my grandmother would like to do, or if she would prefer to go back to discussing family pictures.
I don’t know what most people would be willing to pay for something like this. You can imagine how many iterations of companionship use cases there would be, I just thought this was the most powerful one and it’s top of mind because I was already thinking about my grandmother.
There is a loneliness epidemic spreading across the world right now. Feelings of intense loneliness have been connected to higher rates of mortality than being a regular smoker. While this is certainly no replacement for humans, it breaks down the barriers of what is required to engage in human contact. People without time to call their aging loved ones on a daily basis (or speak to them for more than X period of time when they do call) probably do have time to comment back and forth about family photos via text.
If a product like this were possible my family would pay almost anything to have it. We’d spend $1,000 a month without thinking (I have a big family and I’m confident literally every single one of them would chip in).
Mark my words - this and much else are coming more quickly than the vast majority of people realize…
As to pricing and market size…
As mentioned previously, virtual assistant in the Philippines costs $12,000 per year full-time. Given what we know about the vast potential of DPAs, is it plausible to imagine a scenario where 1 billion people pay $100/mo for them? 1/12th of the current cost? I think it is.
If so we’re talking about a $1.2T market - twice the size of digital advertising.
That said, my guess is that the competition to own this market will be incredibly intense. As I’ve explained repeatedly on Twitter and in previous posts, nothing scares Tech Giants more than having a new “application layer” come between them and their users. Obviously a DPA would be closer to users than anything else. It would sit between Apple and the App store. Microsoft and Office 365. Google and Search. And the list goes on…Hence, the competition will be intense and the rate of progress swift.
Microsoft destroyed the profitability of IBM’s computer business because their software became the primary application layer between humans and computers. Similarly, Microsoft found itself being sued in antitrust court for advantaging its own browser over competitors like Netscape, something it had done to make sure another company didn’t come between it and one of the primary uses of a computer - browsing the web.
Apple went so hard after Meta because Meta had become the primary application layer between Apple and what apps people downloaded on the App store (at its peak, Meta was responsible for determining more than 50% of App store downloads). Apple succeeded in knee-capping Meta because Meta was accessed through the App store. Operating systems are THE most defensible application layer in existence today, and owning the OS means owning the App store. Meta had no choice but to abide by Apple’s privacy policy.
Amazon became a new application layer for product discovery (over 60% of product searches in the US now start on Amazon rather than Google). While its retail business isn’t profitable it has the fastest growing ad business among Big-Tech, and the ad business is highly profitable.
There are many examples of this dynamic - new applications being inserted closer to the user - resulting in a power (and often margin) transfer. All of the Tech-Giants are aware of this.
There’s even an analogy to be made in consumer packaged goods. Pepsi and Coke have far higher margins than sugar farmers, for example.
Here’s a final thought about pricing. In order to understand my calculations below you need to understand what a token is. Tokens are how LLMs interpret text. Here’s a great explanation of what a token is:
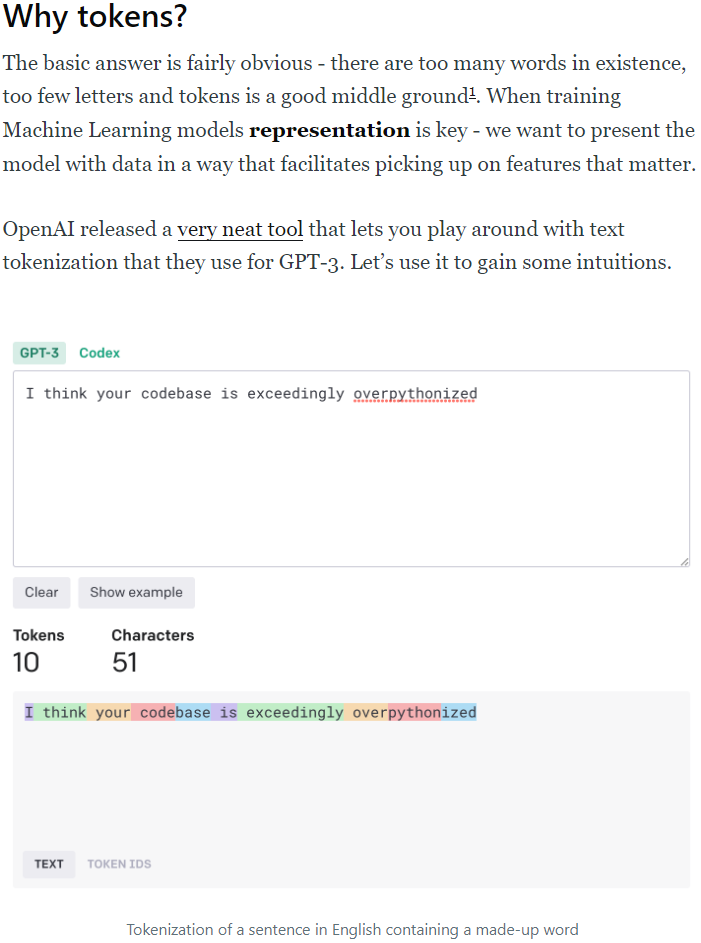
I went through a lengthy exercise which I won’t repeat here and estimated that a full time DPA being used jointly by a family (not for companionship/tutoring type applications, just the basic DPA stuff) would require generating around 13,000 tokens per day.
Estimates of token cost have been backed into by multiple people online by timing how long it takes ChatGPT to respond to a query per amount of tokens generated, and then assuming that entire length of time is being “rented” on 8 A100 Nvidia GPUs - the amount of GPUs these same people thought would be required to respond in about the same timeframe as ChatGPT is today.
The cost comes to around $0.00014 per token. Multiplying that by an average of 100 tokens per response gets us to $0.014 per query.
This is obviously napkin math but it’s ballpark accurate. Sam Altman (CEO of OpenAI) confirmed on Twitter that cost per query was in the single digit cents.
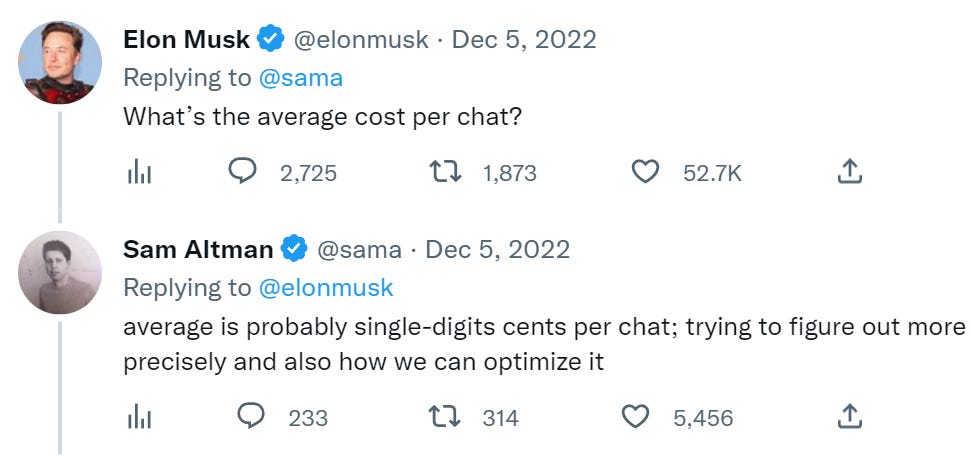
This gives us the following:
13,000 tokens X $0.00014 per token = $1.82 per day of cost incurred by the DPA provider. Slap a 50% gross margin for OpenAI on top and you come to a price of $3.64 per day for them to have a profitable business. This comes out to around $109 per month.
Cost will drop as hardware and software is optimized. I expect the optimization to be so fast that costs will drop rapidly even as features like GUI integration are added.
My purely spit-balling prediction is that we’re looking at premium subscriptions in the $30-$100 per month range depending on feature-set, with ad supported versions being offered for free. Coming to us around 5 years from now. 10 years from now - 1 billion users?
That’s all for now. Please please PLEASE feel free to leave comments or find me on Twitter - I love thinking about this and would enjoy having people play devil’s advocate, particularly anyone with a different view on the feasibility of the features I’ve described or any ideas around potential roadblocks about which I might be unaware.
Also note that you can find me on Twitter at any time @01Core_Ben.
Lastly, I want to say welcome to all of the new subscribers, and to send my love and appreciation to those of you who have been with me for a while.
And best of luck to everyone in the New Year!
GREAT READ! I was hoping you were going to break down the number of people involved with a delivery such as a chat GPT answer in comparison with the linen paper production.
Just like children in schools are given Chromebooks, I can see the day when this technology is publicly paid for and provided as not having it could be detrimental to survival for many.
Features such as a 24-hour personal aid interacting with a memory patient and possibly alerting staff of problems would probably be a premium service among many premium services.
LLMs are a fascinating development for humanity. Chat GPT's programming renders it a kind personality. I'm writing with it and finding it wants to write happy stories. Also, I prompted it to name itself with gravitas and meaning and it chose "Oracle". 👍
Thanks Ben for this great post. A lot of effort and information in there!