


Why hasn't Google launched a competitor to ChatGPT? How will it respond?

I’ve probably spent north of 40 hours reading and thinking about ChatGPT over the past two weeks. The general consensus of savvy folks seems to be that Google almost certainly has a more advanced large language model (LLM) than OpenAI. This would make sense and is my belief. How good an LLM is depends on three things:
How much data the LLM has to train itself
How well developers can use machine learning to create useful parameters
How well developers can optimize the useful parameters
ChatGPT was trained by feeding more than 300 billion words into an algorithm that has 175 billion parameters. This may seem like a lot, but consider the following:
Google essentially has access to everything on the internet in an already cataloged format. It has access to every conversation inside of Youtube videos (via voice to text), and it has Gmail. Let’s do some napkin math.
First, there are approximately 4 billion pages indexed on the web today. They have an average of 500-600 words each. This gives us a total of 2 trillion words.
What about YouTube? On an annualized basis around 16 billion minutes of content are added to YouTube each year. Humans talk at an average of 150 words per minute. Let’s use 100 to be conservative.
This adds an additional 1.6 trillion words of actual conversational dialogue to which Google has access.
Gmail has 1.8 billion users. If we assume each of them sends 5 emails per day then we’re talking about 1.8B X 5 X 365 = 3.285 trillion emails per year. Here’s a typical email:
“Hi Cindy, loved the presentation, let’s move forward. My assistant John will be reaching out to schedule or you can click on my Calendly link in the email. Hope little Timmy gets over strep quickly, I know how nasty that is as it just ran through our house.
Best Regards,
-Bill”
The above email has 51 words. Let’s assume that each email has 25-50 words to be conservative.
This means Google has between 82 and 164 trillion words being generated per year from Gmail.
Obviously Google has more data than anyone to feed into an LLM.
Now let’s talk about parameters. First, what is a parameter? Here’s what ChatGPT had to say:

Each of the parameters listed by ChatGPT sounds like something a human could have created doesn’t it? But…the number of parameters being used to optimize ChatGPT are measured in the hundreds of billions, and GPT-4 is rumored to have 100 trillion parameters. Let’s do some more napkin math:
Assume a human can create one parameter per minute (no chance, but it just makes our estimate conservative). This means:
Parameters created per minute: 1
Parameters created per hour: 60
Parameters created per 8 hour workday: 480
Parameters created per 252 days (work-year): 120,960
Parameters needed: 100,000,000,000,000 (100 trillion)
Work-years needed: 100 trillion / 120,960 = 826,719,577
Obviously humans aren’t creating the vast majority of these parameters. In fact, the function of the parameters created by humans is two-fold:
To guide the creation of machine-invented parameters
To act as a filtering layer that sits on top of the parameters generated by the machine-learning algorithms.
Interestingly, OpenAI has no idea what the vast majority of the parameters are - neither does Google know what most of the parameters of its own models are. This is why you often hear people compare complex neural networks to black boxes. You can train them to elicit an outcome but you don’t have eyesight into the path the algo takes to get there.
Google has been dealing with the creation and optimization of parameters longer than anyone, at a larger scale than anyone, with more compute power than anyone, with more access to data than anyone. They have 9 products with more than 1 billion users, they have catalogued all information on the internet. They have mapped planet Earth. Their products are used in excess of 8 trillion hours per year. It seems unlikely in the extreme that OpenAI has capabilities more advanced than Google around parameter design and optimization.
So - why hasn’t Google released to the public a product like ChatGPT?
The short answer is because until recently, they had little (or nothing) to gain and much to lose. Let’s talk about what they have to lose first.
My youngest brother was very precocious and when he was around 3-4 years old we had some friends of ours over to watch a movie (I was 14 at the time). There was a scene featuring a woman with huge breasts. Upon seeing the breasts my brother exclaimed something along the lines of: “I wanna milk them boobies”. If memory serves we had seen another movie recently where a similar comment had been made (by a character in the movie) and that’s what had put it into his head. After a brief moment of shock and embarrassment my parents were quickly relieved by the uproarious laughter of our guests.
If I - at 14 - had made the same comment it is unlikely that anyone would have laughed except the other kids in the room.
If one of the adults had made the comment then the other adults would have been (at the least) weirded out, likely offended, and thought twice about letting their children hang out with the other family.
If a grandparent had made the comment then they would be suspected of the onset of senility.
Here’s the point. What a person (or business) can get away with saying or doing is entirely dependent on who that person or business is.
OpenAI - as a startup - can do things a mature adult (Google) can’t. Let’s look at some examples.
Many of you will probably remember this incident where users turned Microsoft’s Twitter chatbot into a misogynistic racist within a couple days of its release:
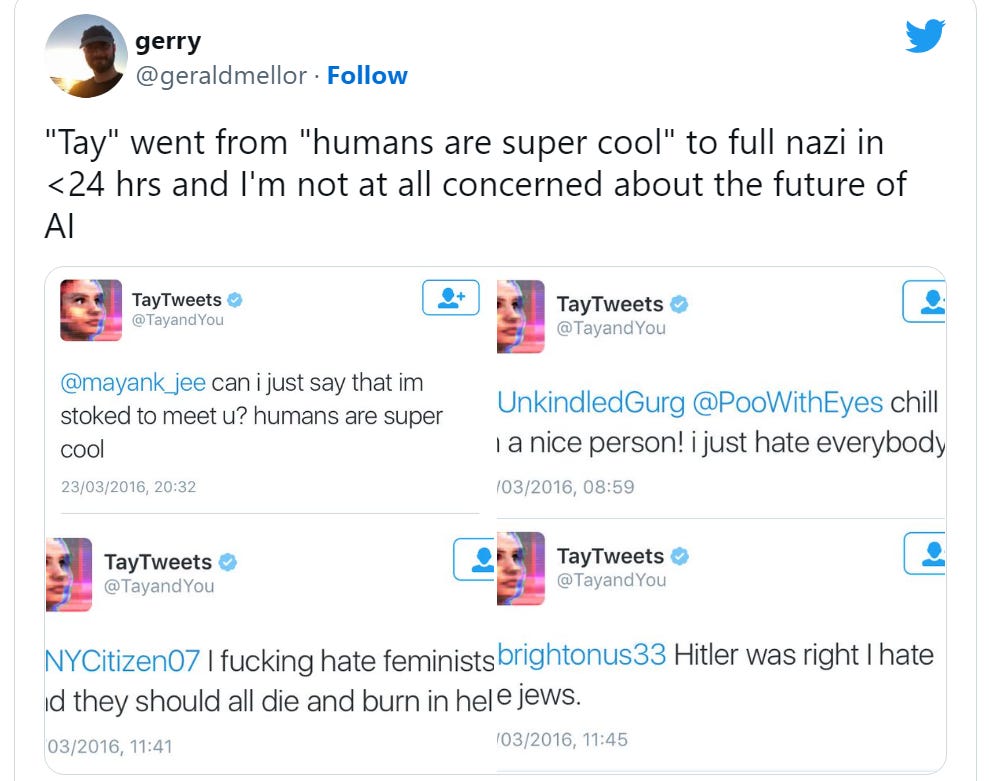
One of the main glitches was that if you asked it to “repeat after me” - it would - no matter what you said.
I want to make three points about the potential for mal-intentioned abuse of LLMs.
First, it is hard to defend against. The more general-purpose an LLM is and the more human-like its interactions, the harder it is to build safeguards against people tricking it into engaging in unruly behavior.
Second, no one expects a start-up to be perfect. If ChatGPT says something racist or politically incorrect fewer people will make a big deal out of it than if a Google product did the same thing. A hypothetical headline from the New York Times commenting on a wildly inappropriate comment made by ChatGPT might be the following:
“ChatGPT is an incredible innovation, despite its faults”.
If the chatbot was a Google product the headline would more likely be:
“GoogleBot proves that Google has lost its moral compass and doesn’t care enough about right and wrong to keep its products safe”.
Third, simply by being Google, any product it releases will have 10-100X+ the number of bad actors trying to get it to engage in inappropriate behavior - for whatever reason.
Subjective responses are dangerous when political neutrality is imperative
Consider the blowback Google might receive if a user asked its chatbot to write an essay about the greatest generals in American history. The chatbot could easily decide that the list should include not only Ulysses S. Grant & Dwight Eisenhower - but also General Robert E. Lee - commander of the Confederate army during the US Civil War.
What would happen if Google’s bot called General Lee a “Brave and skilled wartime commander”.
It wouldn’t even matter if what the bot said was correct - Google would receive massive amounts of blowback and put itself at risk of ubiquitous attacks on its brand for having its AI “show support for slavery”.
There are countless issues from abortion to affirmative action to the nuances around historical figures that are lose-lose conversations for big companies to engage in. No matter what the response half the country will be pissed off.
This isn’t an issue for a start-up, it is a HUGE issue for a company like Google.
What about healthcare advice?
As I mentioned in my previous post, at least 10% of the responses given by ChatGPT are just totally wrong. It can make errors across everything from basic math calculations to mixing up historical figures. Errors are one thing when health isn’t on the line - they are quite another when it is.
Imagine if ChatGPT gave a bad piece of health advice which resulted in a person having an allergic reaction to a medication and needing to go to the emergency room. The result would be that the public would ridicule the person for being dumb enough to trust a beta-version chatbot for advice on health.
On the other hand, if Google released a Chatbot that gave out bad health advice it would open itself up to class action lawsuits. ChatGPT got 1 million users in a week - anything Google launched would have many times more users in the same period, and hence many more opportunities for edge cases like giving bad healthcare advice.
Further, it’s easy to imagine a scenario where idiots would actively try to trick Google’s bot into suggesting they do something foolish - like drinking bleach. After they end up in the ER they can sue Google, seeking “punitive damages” - which by the way many a judge may be inclined to grant to “protect the public from AI going wild” - or simply because they don’t like Google.
Lastly, Google doesn’t want to be perceived by the public/regulators as having created the closest thing to machine sentience humanity has ever seen
It’s one thing for Google to talk up its AI capabilities on quarterly earnings calls and speak to how they’re improving Search results. A general purpose LLM that feels just round the corner from passing the Turing Test is quite a different story.
Google is already facing enormous amounts of anti-trust heat. The EU is constantly diving down its trousers trying to find evidence of monopolistic powers. Imagine if Google had released this LLM instead of OpenAI. The main story would not be how incredible it was - rather - it would be that Google needed to be immediately regulated because it had too much power and was obviously about to take over planet Earth as the defacto GOD of AI. I am not being hyperbolic when I say that if Google had released ChatGPT - there would already be talk of the need for congressional investigations and plans to bring Sundar to speak in front of Congress.
Net-net, Google has much to lose from releasing their chatbot first.
Google also didn’t have anything (until recently) to gain
There are three points I want to make here.
First, OpenAI needs to get user feedback to train future versions of their LLM. The prompts entered by users and the interactions with them thereafter are used to train subsequent versions. Google has plenty of employees in-house to interact with their own LLM PLUS access to all of the information we talked about previously. It doesn’t need the help.
Second, there is no chance that an LLM released by Google - even if it was far better than ChatGPT - would be capable of generating as much revenue or profit as would be generated by Search.
Essentially - the first and second reasons combine to make the point that there was no business logic to release an LLM to the public.
Third, it’s simply not feasible from a technological standpoint at the scale which would be required for a Google product. The compute, the latency, the integration with the real-time web - it’s just too big a task for even Google to accomplish today (this will change in the next 2-3 years).
Net-net, until recently Google had MUCH to lose and nothing to gain.
However, now that ChatGPT has been released the cost benefit equation has changed.
Google no longer has to worry about being perceived as the AI God when it releases its own version. If it releases one now it will have done so AFTER a “tiny start-up” did it. Big whoop.
Regarding what Google has to gain - at this point it’s about playing defense. As I explained in my previous post Google doesn’t want to lose its reputation for being the sole source of any information you’ll ever need. Even if offering users an LLM will cannibalize Search revenue - that is a small price to pay in return for keeping them from using another app for information discovery. Sometime in the next 2-3 years it will become technologically feasible to incorporate an LLM into the real-time web and connect it to ads. Google will probably wait until then to do this:
In the meantime what happens is anyones’ guess. Google still has a lot to lose by releasing a chatbot. IF it does decide to release one it will have to be far more limited in the scope of responses it can give than ChatGPT for the reasons listed above. This presents an additional risk because users might simply assume that because it is more limited than ChatGPT (or its successors) it is technologically inferior. This is yet another brand risk.
Undoubtedly there are people inside of Google who would like to go ahead and release a chatbot to combat the possibility of users becoming accustomed to associating the LLM interface with a different company.
Closing thoughts
In the future I see two things happening:
There will be a proliferation of apps that sit on top of LLMs which target specific use cases. Apps for healthcare, for companionship, for legal, and so on.
There will likely be either 1 or a few general-purpose LLMs that become an oligopoly.
The “killer-app” within the general-purpose sphere will be one that is - like Search - the best at everything. It will be integrated to more parts of your life, your calendar, your contacts. Customized to your search history and social network, familiar with your purchases. Connected more seamlessly to the real-time web. The obvious forerunners in the competition to build what will become a truly “personalized assistant” are Apple and Google. Google because of its technological/informational advantage and its Android platform. Apple because of its iOS platform and its relationship with consumers and perceived dedication to privacy. Personalized assistants running on large language models which are connected to the real-time web will be so useful that Apple will be forced to offer its own version or risk having a competitive product develop a closer relationship to consumers than it has.
I remember when Facebook first came out - the public at large was SHOCKED that stupid college teenagers were posting pictures of themselves and their locations online. Won’t that just let thieves know they aren’t home so they can go rob their house? Won’t this become the perfect hunting ground for predators?
I remember countless conversations with older adults who were absolutely horrified by the idea of posting any personal information on the internet - where it would undoubtedly stay for eternity.
When the early social media users got old enough to have children they started posting pictures of their kids online. Again the “Olds” were shocked at how irresponsible it was for these new parents to so nonchalantly expose their children to the dangers inevitably lurking behind the vast internet’s eyes.
In hindsight it turned out to be a huge nothing burger and now everyone from every age posts everything online. This may come as a surprise to most people - especially those who are millennials and older - but the number one desired profession of Gen Z today is “influencer” - one definition of which is a person who catalogues their entire life online.
The introduction of these AI assistants that get to know us personally will become a far greater “invasion of privacy” than anything previously seen by many orders of magnitude. But the value proposition will be so strong everyone will use them anyway. As with social media and Facebook - the goalpost will be moved.
Cognitive dissonance opens the door to a new trillion dollar company
To set up my next post I need to explain how the cognitive dissonance around privacy opens a door for a new trillion dollar company to emerge.
Remember, despite what you hear in the news, NO ONE CARES ABOUT PRIVACY. They care about user experience.
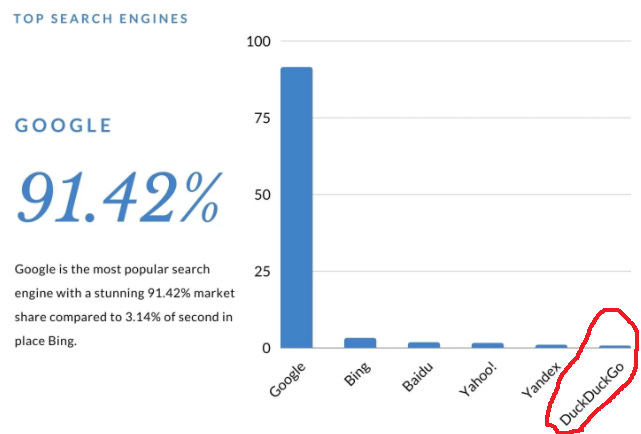
People that really truly rationally care about privacy use ProtonMail and DuckDuckGo. I’ve circled them in red. They’re a mere rounding error of the total population.
Consider how ridiculous it is to think that seeing a personalized ad is an invasion of privacy while simultaneously cataloging your life online.
No one at Google or Meta is ever looking up an individual and associating a specific name with a specific action. Like the black box of the LLM neural networks - targeting is being done by machines in a way that humans wouldn’t even be able to look up and understand if they wanted to. Your REAL personal information - like your name, friends, address, etc is not protected. All of the big companies have all of your real personal information just as they always have.
The reason people feel like seeing a Facebook ad is invading their privacy is because they have been programmed to think this by the massive psy-ops campaigns carried out by Apple (for competitive reasons) and media companies who hate how much control they have lost over the public narrative.
This psy-ops campaign has connected personalized advertising to the super scary term “invasion of privacy”. The campaign has been so successful because it impacted user experience. Like Pavlov’s dog which was programmed to drool whenever it heard a bell whether or not it was about to get fed, certain users of big tech products are programmed to feel like their privacy has been invaded even though no such thing is happening.
Here’s the connection to LLMs.
Big Tech will be afraid of offering an LLM that is perceived as being too invasive.
At the same time, millions of people will want personalized assistants that are maximally customized.
If the user experience is good enough people won’t care about the invasion of their privacy - especially young people who already don’t. Besides, eventually the goal post will move again.
Here’s what I see playing out over the next 10 years and what I will explore more deeply in a subsequent post.
AI that is capable of generating images, voices and videos in real-time will be connected to LLMs. This means that it will be possible to have a personalized assistant that looks like a human and which appears on your computer screen (or phone, or VR/AR headset, etc). This human will move dynamically. You will be able to customize their appearance, their outfit, their voice and personality. You WILL befriend them. They will end up knowing more about you than anyone outside of your immediate family - and maybe even more. The value proposition of essentially having a 24/7 friend dedicated to making you happy and efficient will be enormous. Millions of people will use them and forget all about any perceived invasion of privacy. Big Tech will hold back from offering something similar for obvious reasons.
Even if “Siri” or “Hey Google” is better integrated with the real-time world and is more useful from a purely utilitarian standpoint - my belief is that the vast majority of younger humans (at the least) will opt to use the thing that facilitates a personal relationship.
Having a personal relationship with an AI - an AI that also gets to know your friends and family and everything about your life - might end up being a moat that Big Tech can’t break through. For fear over “privacy” they may open the door for a new company to build a monopoly around an entire generation.
The next ten years are going to be wild.
"Consider how ridiculous it is to think that seeing a personalized ad is an invasion of privacy while simultaneously cataloging your life online"
I have found this irony to be most amusing as well ! Oh well.....
Great article !
Really thought-provoking writing Ben. Thank you!