

Predictions for the humanoid robot ("Synths" for short) market by 2035
Predictions for the humanoid robot ("Synths" for short) market by 2035


Topic Summary:
Why don’t we already have humanoid robots?
How will the funding landscape evolve over the next ten years?
How fast will production ramp?
Will multi-modal data capture by Synths be the final unlock for AGI?
How big is the TAM for Synths?
Prediction Summary:
Synths will have human level dexterity by September 2025
Funding into synthetic humanoids will double every year for the next 10 years
Production volume in 2032 worldwide will be ~14 million units
Human equivalent embodied AGI will arrive in 2030
There will be more than 1 billion Synths worldwide by 2040
Synth market cap will cross $10 Trillion by 2035
Why don’t we already have humanoid robots? (henceforth “Synths” short for Synthetic Humanoids)
Humans can make some incredibly complex things already. Take an extreme ultraviolet lithography machine made by ASML as one example:

An EUV machine is used to etch the most advanced semiconductors using ultraviolet light. It costs $380 million, contains 100,000 parts, requires 250 specialized engineers to assemble, and 250 crates to ship. Surely this machine is more complex than a Synth?
An example a little closer to home would be Boston Dynamics’ robot capable of doing parkour:
Alas, Boston Dynamics has been showing us videos of impressive feats for years - meanwhile commercialization never materialized.
The reason we don’t have Synths is because the intelligence piece has been missing. Synths need two things to reach human-level functionality:
A brain
A “skeleton”
Until recently building the brain seemed like an impossible pipe dream. So, companies like Boston Dynamics mostly worked on the skeleton - “hard-coding” what movement, balance and object recognition functionality was required to test components. Funding into the skeleton has been limited to a rounding error in the grand scheme of tech investment because there hasn’t been any path to market without the brain.
Advances in compute over the past ten years have been astonishing. Jensen Huang - Nvidia’s CEO - cites a 1 million X improvement over the past ten years. This chart shows inference improvement for GPT-3 across different generations of Nvidia chips going back to 2021:

More powerful compute is making literally everything possible, from ChatGPT and other language models to new video generators that “understand” the laws of physics. Watch this video by Marques Brownlee for a quick primer:
At this point the existing intelligence is perfectly capable of acting as the brain for Synths. While we will obviously continue to improve intelligence over time and at an increasing rate - it is no longer a limiting factor in bringing Synths to market.
This doesn’t mean they’ll arrive tomorrow. The new underlying architecture of synthetic brains is built on neural networks - meaning that even after we have a “brain” we still need to train it (a 6 month old Einstein could not have solved relativity even though it had the same brain). It’s not obvious how long this training will take, but we have some clues.
Rumors are that robot dexterity and movement speeds are improving at a rate of about 100% every 6 months. This jives with my personal observations.
This video comes from Figure AI:
Watch this with a timer in your hand and record how long it takes from the time the human asks the Synth to do something until the task is complete. I went through this exercise and the answer is surprisingly consistent. The robot takes about 8 seconds to do something a human could do in 1 second (equivalently, a 16 second task would take a human ~2 seconds). This ballpark figure holds accurate across the different tasks in the video. I didn’t bother to do the exercise again with older demos but I can say it is an enormous improvement and could easily be twice as fast as demos we were seeing last year.
What’s incredibly neat about this trend is that we (the public) can easily monitor it to see if it remains on track. Just pay attention to demos being released 6 months from now and do a before and after (or just keep an eye out for posts from me as I’ll be staying on top of it).
This leads to my first prediction in this post: Synths will achieve human level dexterity by September 2025:

Worth noting, my definition of human level dexterity is not as fast as Usain Bolt with the hand eye coordination of Lionel Messi. It’s more akin to saying that Synths will be equivalent to elderly people who are perfectly capable of doing most tasks but not at the same speed as someone who is younger and proficient.
A question begs - once Synths achieve human level dexterity - will they keep on going? I have two answers to this:
Yes of course.
Applications will probably be limited to the military and/or special situations mostly outside the public eye.
Humans are not used to “non-human” speeds. Consider the case of an older person who is frail and with poor balance. It wouldn’t be safe to have rowdy children playing chase underfoot. They need the people around them to move at speeds they are capable of responding to.
Similarly, it wouldn’t be safe to have Synths running around society and completing tasks at rates that humans weren’t adjusted to interacting with.
Long term I believe we’ll have Synths that are functionally equivalent to Terminator. Capable of doing things like scaling this table by digging its hands straight into the wooden legs or maybe even jumping straight to the top.

Only the laws of physics are holding us back. But such robots won’t be permitted anywhere near peaceful citizens.
How will the funding landscape evolve over the next 10 years?
The amount of funding going into any given space is mostly tied to the size of the total addressable market (TAM). Today the largest recipient of funding is data centers - which address the heretofore largest non-commoditized TAMs of “cloud computing” and more recently “general digital intelligence”.
There are obviously all sorts of other factors that have an impact shorter term, for example:
stage of space (early R&D, early adopters, found product-market fit and scaling, etc)
interest rates
economic situation
hype (seriously)
etc..
Regarding Synths, the TAM will be the biggest of all time (TAM estimation later in the post). Beyond the obvious “work related” use cases, Synths will eventually be perceived as helping advance national security, solving climate change, fixing our loneliness epidemic, and I’m sure some things I haven’t thought of. With that said, there are fundamental limits to how fast companies can put money to work.
Figure recently received a $675 million investment from companies like OpenAI, Microsoft, Nvidia, Jeff Bezos, Intel, and the list goes on…
YTD funding across the space is impossible to gage due to in-house projects that don’t disclose figures (most importantly Tesla’s Optimus, BYD likely a big spender too), but it’s safe to assume that the amount is already >$1 Billion just in the US alone. My best guess is that this figure doubles every year for the next 10 years (albeit with some volatility). This is what that would imply:
$2 billion in 2025
$4 billion in 2026
$8 billion in 2027…
$16 billion in 2028
$32 billion in 2029
$64 billion in 2030
$128 billion in 2031
$256 billion in 2032
$512 billion in 2033
$1,024 billion ($1T+) in 2034

Note - when I say “funding” I’m including the raw material and human capital costs of building the Synths.
Funding will be almost entirely R&D for another 4-5 years after which point the lion’s share will be allocated to capex - building the factories that will build the Synths - and shortly thereafter COGS.
Interestingly, this jives with my prior prediction that human level dexterity will be solved by the end of 2025. My best guess is it will take a couple of years to plan at-scale production (need building permits and designs, chip architectures, complex machining, etc). It seems reasonable to assume that at-scale production planning won’t start until Synths have achieved human level dexterity (how could it begin before they know the final components?), which implies breaking ground on a new manufacturing facility somewhere in 2028.
How fast will production ramp?
EVs being designed with hopes of full-self-driving capability are the closest analogy we have to Synths. Both are essentially “smart-robots” that need to be able to understand the world around them using vision. So, we’ll use Tesla’s financials and production capacity as a baseline to estimate what the above spending levels imply in terms of Synth production.
Assumptions:
Synth Gigafactory costs the same to build as any other Gigafactory (~$10Billion). Interestingly - modern FABs cost ~$15Billion to build and they make the most advanced products humans create at scale (chips) - this is nice b/c it’s only possible to estimate something like this within an order of magnitude - and if the two most advanced manufacturing facilities in the world today cost $10B and $15B respectfully, we should be accurate within a single order.
Cost to produce each Synth is 1/2 of what it costs to produce a Tesla: ~$18,500.
Synth production capacity per Synth Gigafactory operating is .5X the capacity of an auto Gigafactory (~1m per year) in year 1; 1X in year 2; 2X in year 3 and 4X in year 4 where it gets capped out.
Tesla R&D on Synths achieves parity with 2023 R&D and grows thereafter at 50% per year.
Now if we take our above figures we might end up with something like the following:

The above table assumes the same mix between R&D and production for “Other” as for Tesla. It also assumes similar production costs per unit. This is virtually guaranteed to be off - but not by enough to change ballpark figure.
We have now got two additional predictions:
Funding will double every year for the next 10 years
Global production volumes will hit ~14 million by 2032
Will multi-modal data capture by Synths be the unlock for human-equivalent AGI?
First let me provide my definition of AGI: Something capable of performing all human activities at the level of an average human with the sole exception of biological reproduction.
Put differently, a digital AGI would be capable of doing anything a human could do on a computer or mobile phone. A physical AGI would be capable of doing anything a human can do period.
I’ve previously hypothesized that multi-modal inputs might be what is required to get us to full AGI. What could possibly be more multi-modal than a humanoid robot?
The following snippet is from a post I wrote in September of last year. (Feel free to skip ahead if you already read and remember this post)
People (including me in the past) have often pointed out that a driverless car is still worse after being trained on hundreds of millions of hours of video than a teenager is after only 15 hours of practice. Doesn’t this imply that we are nowhere near reaching artificial general intelligence?
Not necessarily.
A teenager has experienced 131,400 hours of life by the age of 15 (365 X 24 X 15). However, each hour of human life incorporates a far higher data load than an hour of video watching - in large part because the human is taking in data multi-modally (e.g. sound, vision, language, smell, touch, etc).
Consider the data load of a child “experiencing” someone dropping a vase.

Inputs/learnings would include the following concepts:
Gravity - the vase falls
Value - dad yelling in the background that the vase was expensive
Pain - mom instructing everyone to stop walking until the glass shards had been picked up
Material science - the glass shatters
Cause and effect - associating the clash of breaking glass with the future danger of needing to avoid shards on the ground
Smell - blood smells
Sound - that which fragile things make when they shatter
Language colloquialisms - hearing the older brother say “Well that’s just fucking great”, and learning that in this case the comment actually means the opposite of what he said
I could literally go on forever.
Our human ability to take in data multi-modally makes us far more efficient synergizers of data than computers. And - virtually all of the information needed to learn to drive is something we have been taking in since the day we were born. The reality is that everyone essentially knows 99.99% of what they need to drive before they even start learning.
Consider the example of teaching a car what to do if it sees a child wobbling on a bicycle up ahead. Before it starts its training it has no concept of “wobbling” (e.g. the laws of physics). It doesn’t know that wobbling could lead to falling over. Now put yourself in the shoes of a driverless car. If your only method to learn about the concept of “wobbling” was to watch videos of people driving - how many hours would you need to watch to run across enough examples of “wobbling” to learn the concept? The answer is some very large number.
As another example, consider the situation of driving on the highway and seeing something in the road ahead. It only takes a human milliseconds to determine whether an object is likely to be light or heavy, and whether it is worth swerving around or pummeling ahead. A human would be able to immediately identify an empty cardboard box as something that it should not risk swerving to avoid and simply run right over. How many hours of driving video would it take to learn what “light” or “heavy” objects look like?
The first (pre-ChatGPT) iteration of large language models were so unimpressive that nobody had ever heard about them.
ChatGPT was so impressive that it became the fastest growing product of all time, reaching 100 million users in a matter of months. Even so it still wasn’t able to perform as well as educated humans on things like SAT exams, AP exams, LSATs, MCATs and so on.
GPT-4 was released less than 6 months after ChatGPT, and is now capable of performing in the 90th percentile on most exams. It received a 5 (highest score possible) on AP Art History, Biology, Environmental Science, Macroeconomics, Microeconmics, Psychology, Statistics, and US Government and US History exams. It received a 4 on AP Physics 2, Calculus, Chemistry and World History. It scored a 163 on the LSATs - putting it in the 88th percentile and well-capable of earning entry into top law schools.
Here’s my point. To-date computers are successfully making up for their lack of common sense and general understanding of how the world works through their ability to process enormous amounts of information. But what will happen when computers are able to take in information multi-modally just as humans do? What will happen when large language models are combined with video, image, sound and eventually touch and smell (yes, folks are working on that as we speak).
Revisit our example of learning what it means to wobble. Here’s how GPT-4 responded to the prompt: “What should a driver do if it sees a kid wobbling on a bicycle up ahead”:

Obviously ChatGPT understands exactly what it means to wobble.
Now imagine how game-changing it will be when machines can also use the entire corpus of text to learn how to interact with the physical world around them…
Today we have neural networks being trained on video (Tesla FSD), sound (ultra-realistic text-to-speech already exists, most people just haven’t run across it yet), images (Midjourney, Stable Diffusion, Adobe’s latest product, etc), and language (ChatGPT/GPT-4). What we have yet to see is someone integrate all of the above into a single product.
I don’t know how much of “common sense” and “general intelligence” comes from each input modality (sight, touch, sound, etc) - nor do I know if all modalities are required to achieve AGI (I doubt it), but after we have robots moving around the world, picking things up and putting them down, watching humans interact, etc - they will have all of the inputs we have.
AGI is closer than most people think…
“Physical intelligence”
The example with the vase illustrates how powerful the data collected by Synths might be in training a general intelligence. A Synth would be monitoring and recording the world around it 24/7, including learning smells and touches. It’s possible that this data becomes uniquely valuable in building a moat around what I’ll call “physical intelligence”. What we’ve seen over the past few months in the generative AI/LLM space (launch of Claude, Llama, GPT 4, image/video generation, apps being built on top of each, etc) - leads me to believe that the underlying guts of AI (at least those which exist today - which have been trained on digital information) may be less valuable than most people think - mostly because a sufficient quantity of data is available to anyone with a billion $ to train a model. (Aside: I think this dynamic changes after AI passes human level intelligence, but that’s a topic for a different post).
Physical data may be in shorter supply - how else would it be captured except by something like a Synth?
The takeaway is that I’m leaning towards thinking that the moat which will be built around the Synthetic Humanoid space may be even stronger than I previously thought.
And now for our prediction: Multi-modal data captured by Synths will unlock fully human-equivalent embodied AGI by 2030
How Big is the TAM for Synths?
Approximately 3.4 billion people are employed worldwide. In the US the share of White Collar: Blue Collar is around 60/40 - but this ratio is flipped in less developed countries (China sits around 53/47). Let’s just call it 50/50. This gives us 1.7 billion blue collar workers worldwide. If we assume that 25% of those could be replaced by Synths then we have a starting point of 425,000,000.
The three other sources of massive demand are people who can afford their own Synth as a “servant” of some sort, and people with disabilities and the elderly who will likely have the government provide them with a Synth as part of Social Security/Medicare/etc. When you look at the cost of providing care to the elderly (ER visits/falls, messing up medication dosages, surgeries that could be prevented if signs were caught earlier, etc) it is quite obvious that the cost of providing a Synth would be lower than the cost of managing care using our current system.
We might end up with something like the following:

The production ramp might look something like this:
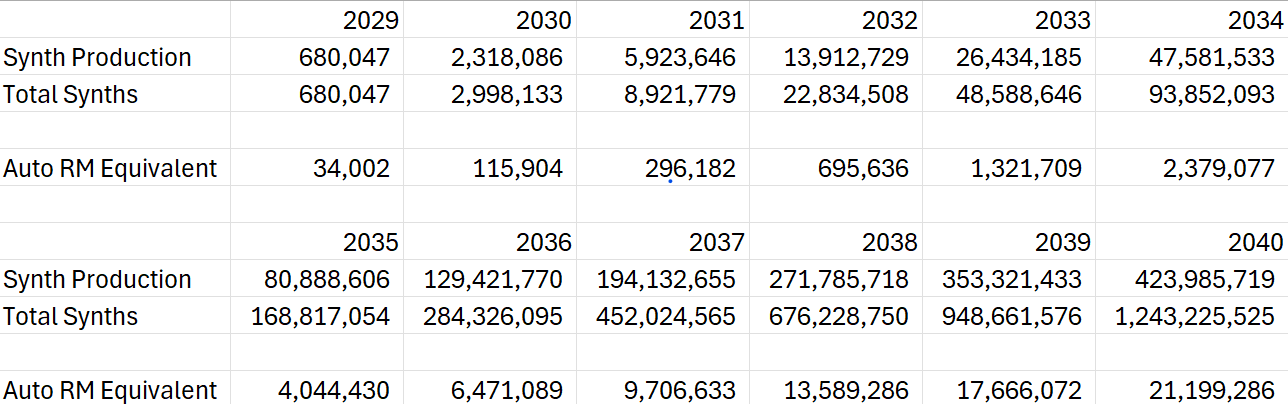
Prediction: There will be over 1 billion Synths worldwide by 2040
Each Synth weighs approximately 1/20th of what a car weighs. I made a new line item to put into perspective what the Synth production implies in terms of raw materials to head off any criticisms that this level of production will be impossible. Note that nearly 60 million new vehicles are sold every year worldwide, and our raw material equivalent if we produce 423,985,719 Synths in 2040 is only ~21.2million vehicles.
Revenue per Unit and Profitability
My best guess is that Synths will follow some form of Wright’s law cost decline. Essentially, for every X% increase in unit production there will be a corresponding Y% decrease in cost per unit. I’m going to assume the following:
10% cost decline per doubling of production
30% consistent gross margin per unit on unit sales w/ 12.5% Net Margins
Subscription revenue starts at 20% of unit cost and increases by 2% per year thereafter
Subscription margins are 35% Net
This gives us the following:


If we use the above assumptions and assume that the forward multiple on net profits remains constant at 29 then we have the following for total market cap across the space:


Note that the market cap crosses $10 Trillion in the beginning of 2035.
This leads to our sixth prediction: Synth market cap will cross $10 Trillion by 2035.
Fun closing thought w/ some napkin math
It takes 10 men 6 months to build a 3,000 square foot house (assuming they have the requisite knowledge). This is the same thing as saying it takes 1 person 1 year to build 600 square feet.
There are 340 billion square feet of buildings (houses, offices, industrial, etc) in the US.
It would therefore take 1 person 340 billion / 600 = 566.67 million years to re-construct all buildings in the US.
100 Million robots capable of building at the same rate as a human could therefore construction - from scratch - every single building in the entire united states in 5.67 years.
We’re going to have 100 million Synths someday - the possibilities are effin’ WILD.
I think you're close enough. Unfortunately, or perhaps fortunately, at 77 I'm unlikely to see the full effects.
But ti's going to be "Effin' WILD" for sure.|
I'll try to brace my grandchildren as much as I can.