


Generative AI and the shrinking time-gap between unrecognizable realities

The year is 2033…
You slip on a VR headset that is light enough and comfortable enough to wear for extended periods of time. You don’t need an awkwardly shaped controller to navigate anymore. Instead you simply let your eyes focus on the application you want to open and then blink ever so slightly slower than you normally would. As you have come to expect, the application you were looking at is the one that opens. It’s called: “Elysian Simulator”.
Note*** Elysian Simulator is the most popular app on both of the major Virtual reality platforms (Apple’s and Meta’s), and it’s owned by Meta.
The interface of the app looks very similar to Netflix today. There are categories of things you can watch: comedies, scary movies and so on. There are games you can play, ranging from immersive role-playing-games (RPGs for short) to casual multi-player party games. The primary difference between the home screen and Netflix is that none of the movies were produced by a major studio. None of the games were created by Activision, EA Games, or any other major gaming business for that matter. All of the movies and all of the games in Elysian Simulator were created by you or your friends (or other individual creators).
In the top right of the screen is a prominent icon that says “Create”. You let your eyes linger there ever so briefly and then blink again. This opens the simulator.
You say, “Simulator, see if Pandora’s Star by Peter F. Hamilton is available?”
Pandora’s Star is an epic space-opera written by author Peter F. Hamilton. To set us up, here’s a brief description from the Author’s website:
It is AD 2380 and humanity has colonized over six hundred planets, all interlinked by wormholes. With Earth at its center, the Intersolar Commonwealth has grown into a quiet, wealthy society, where rejuvenation allows its citizens to live for centuries, by both rejuvenating their bodies, and transferring their memories into clones.
When astronomer Dudley Bose observes a star over a thousand light years away vanish, imprisoned inside a force field of immense size, the Commonwealth is anxious to discover what actually happened. As conventional wormholes can’t reach that far, they must build the first faster-than-light starship. Captained by Wilson Kime, an ex-NASA astronaut a little too eager to relive his old glory days, the Second Chance starship sets off on its historic voyage of discovery.
But someone or something out there must have had a very good reason for sealing off an entire star system. And if the Second Chance does manage to find a way in, what might then be let out?
Pandora’s star is your favorite book, but it was never turned into a movie or TV show. Fortunately for you Pandora’s Star is available and an icon of the book cover appears on your screen.
You say: “Simulator, would you recommend turning Pandora’s Star into a TV show or a movie?”
The simulator responds: “Pandora’s star has 288,000 words and features dozens of characters and subplots. The author spends enormous amounts of time on world-building and character development. It would not be possible to accurately transcribe the feeling of the novel into a movie, so my recommendation is to turn it into a TV show. If this recommendation suits you, how long would you like your first episode to be?”
You say: “Your recommendation suits me. Please make the first episode two hours long.”
The simulator says: “Very good. With your subscription plan it will take one hour and fifteen minutes to build your first episode to the point at which streaming can start.”
You say: “I don’t have that much time tonight, I’d like to start watching it as soon as possible, what will that cost?”
The simulator says: “With your subscription plan, the upcharge to have your first episode ready for streaming in five minutes is $2.99, would you like to pay the fee?”
You say: “Yes, in the mean time please start building the episodes for the rest of the season and Judas Unchained as well.”
Judas Unchained is the sequel to Pandora’s Star.
You get up to use the bathroom and make some popcorn. Then you sit back down, put on the VR headset, and the first episode begins.
Here’s where things get even crazier.
As you are watching the first episode the face-tracking technology picks up on subtle queues you give off. For example, it notices when something in the corner of the screen catches your eye. It monitors the rate of your blinking and how wide your eyes open. It monitors the tightness of your lips.
Whereas the experience of watching something in a movie theatre is the same for everyone, the experience of watching Pandora’s Star in the Elysian Simulator is entirely unique to you. You are - of course - able to turn your head in 360 degrees and get a view of anything you’d like to see, but for the most part you don’t actually want to have to move your head around while you’re watching. So, you mostly let the simulator’s AI use queues from your face to determine the best viewing angle, the right volume, and when to zoom in on specific features. For example…
The first scene in the book is the following:
The star vanished from the center of the telescope’s image in less time than a single human heartbeat. There was no mistake, Dudley Bose was looking right at it when it happened. He blinked in surprise, drawing back from the eyepiece. “That’s not right,” he muttered.
The AI had originally planned to show you a third party view of Dudley peering into the telescope. When the star vanishes, the AI was going to show you Dudley rearing back from the telescope in astonishment, zooming in on his face.
However, the AI noticed that at the opening moment of the scene your eyes locked in hard on the telescope. It interpreted this as a desire on your part to watch the scene from the perspective of Dudley, peering through the lens yourself to see what he was looking at. The adjustment of perspectives was minor enough that the AI was able to update the episode in a few milliseconds, literally faster than you could blink.
You don’t ever learn that the AI was originally going to show you something other than it did, you simply experience…
We can imagine other customization features. For example if you were wanting to watch something along with young family members you could ask the AI to tone down sexually explicit content by removing the nudity.
Alternatively, if you were watching something with a friend who spoke a different language the AI could enable each of you to watch the movie together, but your friend would hear the movie in her language and you would hear it in yours.
I’ll close the introduction with a final thought. What happens when you have finished watching the sequel? There isn’t a third book…
For an additional fee, you can ask the AI to create a “third season”. You can either let it have a go all by itself, or guide it by telling it which story lines and characters to focus on.
Or, imagine this.
Once you’ve finished the third season generated by the AI you decide that there are some plot holes that could be shored up. Or, maybe the AI introduced an interesting character but didn’t spend enough time building a plot line around that character. So, you start to collaborate with the AI, asking it to spend more time building its story. Or, maybe there was a character that simply wasn’t that interesting, and you ask the AI to update the character’s storyline to include more hardships and surprises.
You end up getting enthralled in the task of creating the best season possible, and before you know it you’ve spent hundreds of hours over the course of a six months going back and forth with the AI until the storyline is perfect. After you’re done you share the new season with some friends who are also Pandora’s Star enthusiasts, and they absolutely love it!
Since you’ve spent all this time you might as well see if you can monetize your investment. So, you do three things:
You list the season you worked on in the Simulator. Anyone in the future who queries the Simulator about Pandora’s Star will now see a “user created season 3” as one of the viewing options. Naturally, there would be a revenue split three ways, with part going to Meta, part going to you, and part going to Peter F. Hamilton.
You list the season you created to Meta’s movie/TV app platform.
You list the season you created to other movie/TV platforms like Netflix. In this case the only difference is that revenue is split 4 ways, with the additional platforms being the fourth recipient.
As it turns out it isn’t just the Peter F. Hamilton fans who like your new season. The season ends up going viral and you rack up 1 million views. Each view earns you $0.10, which translates to $100,000. You don’t know whether you will be able to re-create your hit, but with $100,000 in your pocket you decide to quit your job and give the creator life a shot.
Congratulations, you are now a direct competitor of the Walt Disney Company.
Time between unrecognizable realities
Some of you probably think what I have just described is inevitable. Others may think such a thing will never be possible. Keep in mind that human history could aptly be described as a series of transitions between unrecognizable realities.
The time between these transitions has been shrinking at an exponential pace.
Here’s what I mean.
Homo Sapiens first appeared 300,000 years ago.
It then took 100,000 years for anything material to change in the daily lives of humans. The next big change was the conquering of fire.
The daily reality of living with fire would have been unrecognizable to humans who lived without it. Fire meant cooking, and cooking completely transformed the human diet. Fire also defended us against wild beasts, enabled us to live in larger groups, survive colder weather, and the examples go on…
It would be another 50,000 years until the next big change - the invention of language. Language dropped the cost of information transfer by many orders of magnitude. It also enabled humans to create cultures that were far more complex.
Each of the below inventions would have made a society using them unrecognizable to a society that wasn’t using them:
Art (sculptures and cave paintings): 70,000 years ago
Sewing needles: 50,000
Deep sea fishing (boats/fishing line/etc): 42,000
Long-term human settlements: 40,000-30,000
Ritual ceremonies (and by inference, religion): 40,000-20,000
Ovens: 29,000
Pottery used to make figurines: 28,000-24,000
Harpoons and saws: 28,000-20,000
Fibers used to make clothes and baskets: 26,000
Pottery used for cooking and storage: 20,000-19,000
Prehistoric warfare using weapons (14,000-12,000)
Domesticated sheep: 13,000-11,000
Farming: 12,000 (10,000 BC)
Okay, maybe some of the above wouldn’t have made a society unrecognizable in and of themselves, but paring any few items from the list certainly would have.
Here’s another list of key inventions that took place between 5,000BC and 0 AD:
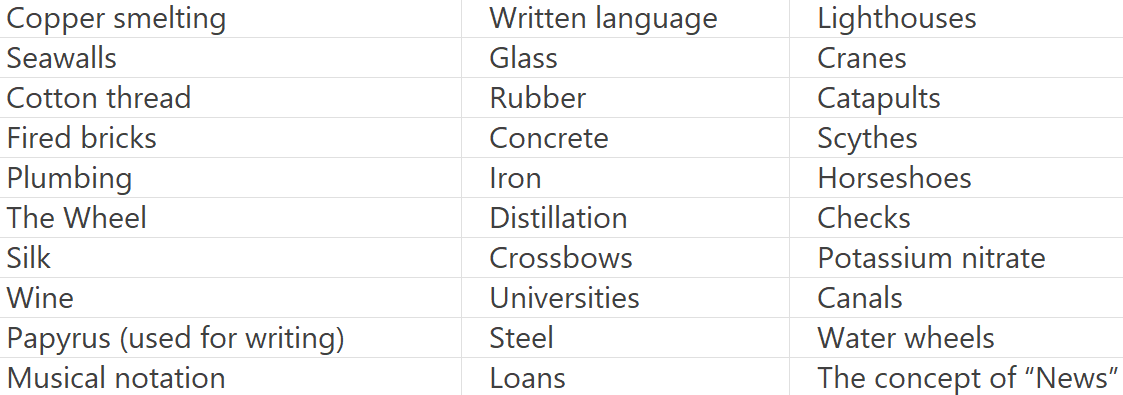
Notice the shrinking timelines?
Let’s jump straight to the 20th century.
The New York Times wrote an article in 1903 proclaiming that human flying machines would take 1 million + years to become a reality. 10 days later the Wright brothers took off for the first time. Sixty-six years later we landed on the moon.
Examples of unrecognizable reality transitions in the 20th century include:
Cars
Radio
Television
Rockets and landing on the moon
Modern medicine
The internet
It only took 10 years into the 21st century to have another transition to a new unrecognizable reality when smartphones gave fully half of the previously unconnected global population access to the internet. Certainly before and after [smartphones and ubiquitous internet access] would qualify.
I DO believe that something like what I described is coming. I’m not sure of the timeline (I’ll discuss that in more detail below), but what I am certain of is that it won’t be long until we will once again be living in a new reality that would feel unrecognizable to people today.
Where are we today?
It would be helpful at this point for you to already be familiar with ChatGPT’s capabilities. I have written at length about them in my three previous posts so I won’t re-hash them here.
ChatGPT is essentially a super complex statistical model that predicts what sequence of words the querier would like to see based on the querier’s prompt.
When I ask it to write a 500 word SEO optimized blog-post about Burt’s Bees dog shampoo - or to write a script in Python to sort a list - ChatGPT attempts to predict what sequence (and in the case of code - format) of words I would most like to see.
The results are nothing short of stunning.
AI image generators work in a similar fashion. Rather than predict a sequence of words they are predicting relationships between pixels. Here are some examples of images generated by Stable Diffusion upon receiving text-based prompts:




Today, AI image generators are unpredictable, don’t do a great job of interpreting common language, and don’t have an easy mechanism for back and forth collaboration. That said, they are mostly less than 1 year old and are improving at a mind-bending pace. For reference, here is the prompt that led to the creation of the image above:
“Residential home high end futuristic interior, olson kundig::1 Interior Design by Dorothy Draper, maison de verre, axel vervoordt::2 award winning photography of an indoor-outdoor living library space, minimalist modern designs::1 high end indoor/outdoor residential living space, rendered in vray, rendered in octane, rendered in unreal engine, architectural photography, photorealism, featured in dezeen, cristobal palma::2.5 chaparral landscape outside, black surfaces/textures for furnishings in outdoor space::1 –q 2 –ar 4:7”
If you wanted to simply ask Stable Diffusion to turn the grassy part into pebbles it would not be able to do that. You would have to adjust your prompt, and it might spit out a completely different image. However, once the memory functions of ChatGPT and Stable Diffusion (and similar models) have been improved the collaboration part will be easier. They will also learn over time what specific users are after and be able to adjust output accordingly, similar to how Google Search is customized to the user.
Can you imagine life as an architect once AI image generation has been combined with knowledge of structural physics?
I recently ran across a company called TrueSync on Twitter that offers a product (mostly to film makers) which enables them to take an existing video of a person speaking and then use AI to change what the person says. The sound of the voice stays the same, the face looks identical, but what the voice says changes, as do the lips to match the new language. You will have to use this link to watch the video (please do, it’s awesome!) because I couldn’t find an embeddable video, but here’s the screenshot:

This is really neat because it will get rid of subtitles or dubbing. People in China would see the same actress, hear the same voice, but instead of speaking English she would be speaking Chinese, and the motion of her lips would match the Chinese enunciation perfectly.
Does knowing that this already exists make my description of watching Pandora’s Star in different languages seem closer?
Here are two more examples (from 2023) of recent advances in text-to-speech AI.
“On Thursday, Microsoft researchers announced a new text-to-speech AI model called VALL-E that can closely simulate a person’s voice when given a three-second audio sample. Once it learns a specific voice, VALL-E can synthesize audio of that person saying anything - and do it in a way that attempts to preserve the speaker’s emotional tone.”

Apple announced a tool that will let anyone turn their eBook into an audiobook with a human sounding voice - meaning they won’t need to pay for the audio production:
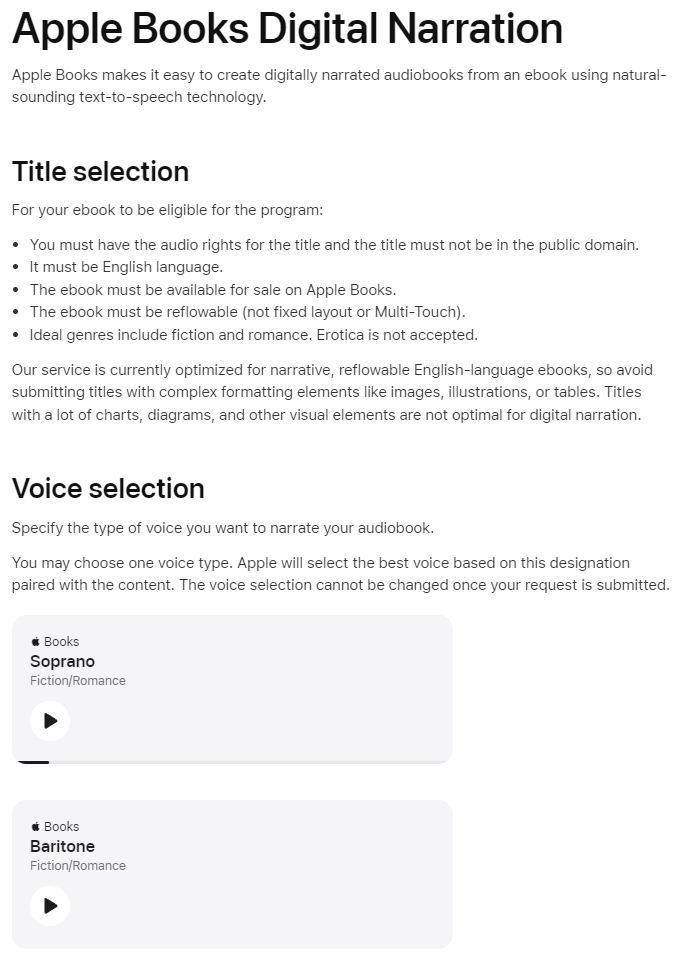
Click the link and listen to the audio quality, it’s wild.
Between Apple and Microsoft and the countless start-ups that are working on similar things, it won’t be long before anyone can upload their own voice - or any other voice for that matter - and have the voice flawlessly speak with emotion and enunciation after having text uploaded.
Generative video today
Generative video has yet to create a product (or even a demo) that will WOW the average person. Here’s a demo released by Google last year that shows what is probably already outdated technology:
Generating video requires orders of magnitude more compute than generating images, but it’s not a terribly different problem. A video is nothing more than a sequence of images.
One thing to take note of is how poor the resolution in the video is. Remember, what the AI is attempting to do is predict relationships between pixels. Whereas inaccurate predictions of text result in nonsensical writing, inaccurate predictions of pixels results in lower resolutions, having too many fingers on a hand (one of the common, creepy errors of AI image generators), and suchlike.
With respect to video, instead of predicting relationships between pixels in one dimension, the AI needs to predict them in two. The first dimension is space, the second dimension is time.
GPT-2 was released on February 14th, 2019. I hadn’t heard of it then. There was no WOW factor. No one outside of the AI and tech community cared. It wasn’t practically useful.
Today ChatGPT has 10 million users two months after launch and is the fastest growing product of all time.
Might we see a WOW factor generative video product sometime in the next two years? Might we see one as soon as the tail end of this year? I know at least one savvy individual who thinks they’re coming sooner rather than later:
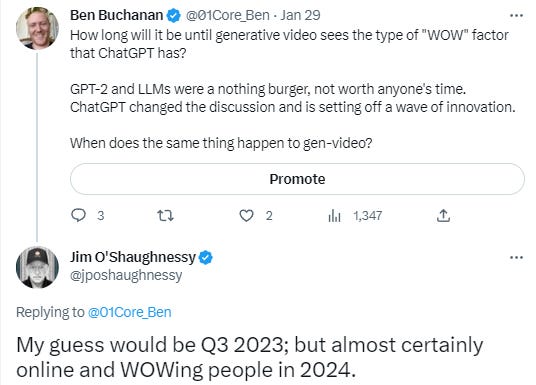
This jives with the opinion of another savvy individual, Emad Mostaque - who is the founder and CEO of Stability AI, which is one of the companies behind Stable Diffusion. Hat tip to Dr. Stefan Bodnarescu @stefan_bod on Twitter, for pointing this out to me.
Emad thinks video will be 1-2 years behind image in terms of having a widely available open-sourced “standard model”. It’s not an exact analogy, but if you consider the AI image generators to have a WOW factor today, that could imply we’re looking at 1-2 years from August of 2022 until we have a WOW factor video product, which is in line with Jim’s comment.
Closing thoughts part 1
Consider the amount of time it would have taken for a graphic designer to come up with something like this from scratch:

5 hours? 10 hours?
Now, instead of requiring 10 hours of work by a bright young graphic designer (very costly), the only cost is renting the GPU time. This is a perfect example of the chart I used in my prior post on ChatGPT illustrating how AI is accelerating the decline in the cost of intelligence:
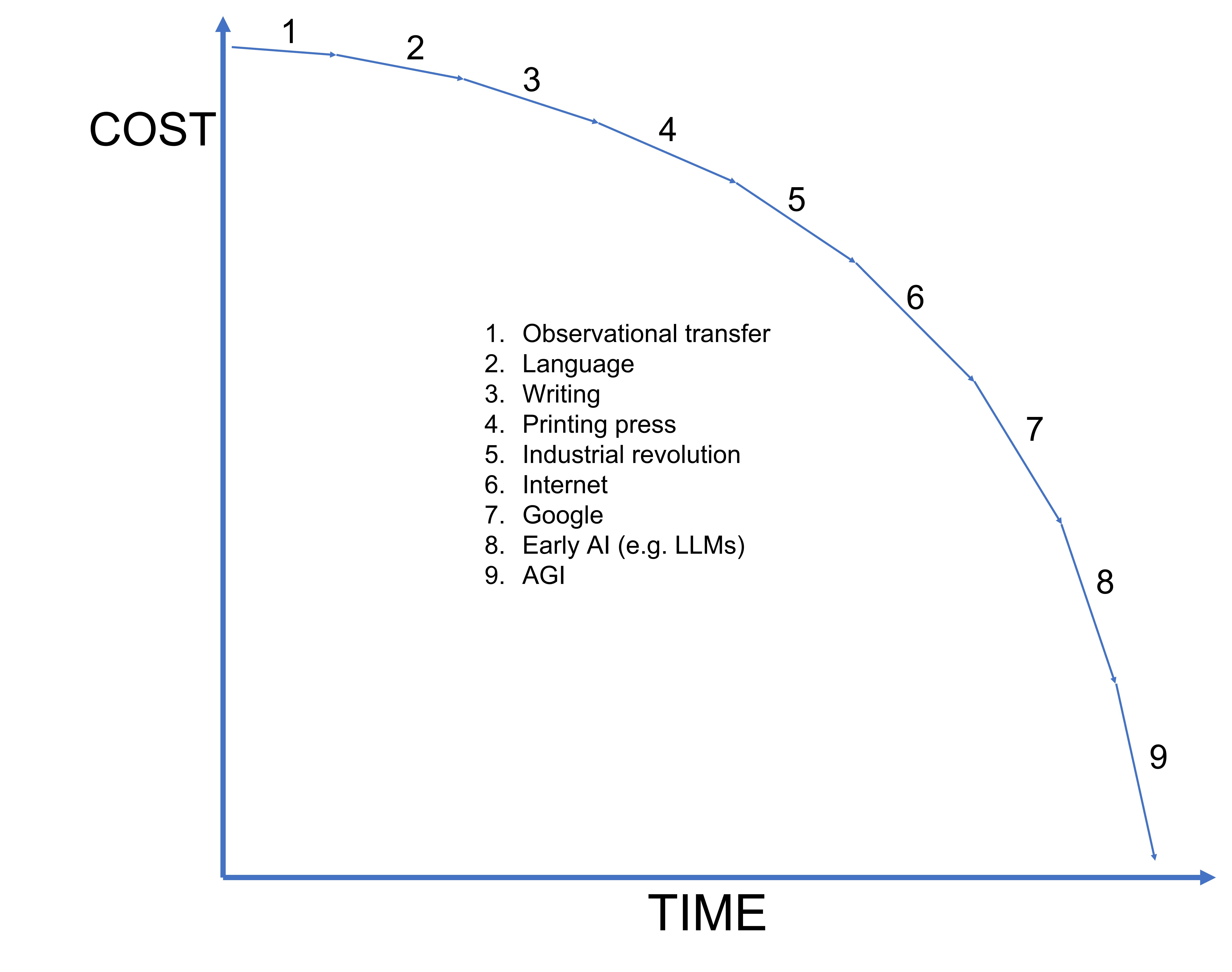
When you combine generative voice, generative text, and generative video - what you end up with is the future possibility that a single person will be able to create entire movies using nothing more than their imagination and some computing power. The impact this will have on the content and entertainment space (among many others) is impossible to overstate.
A person won’t need to be a talented writer backed by a technologically sophisticated team to create an entertaining video. All they will need to be able to do is identify the qualities that make something entertaining.
Consider the following workflow:
User provides guidance to AI as to objectives, plotline, main characters, background setting and so on
AI creates something to start with
User can point out what they like and don’t like about the initial product, and go back and forth with the AI to mold subsequent iterations however they like
Further, consider how many people are world class writers vs. how many people are capable of recognizing world class writing. There are many times more people capable of recognizing excellence than creating it.
Generative AI has the potential to turn the recognition of excellence into the creation of excellence.
What will the world be like when the tens of millions of creators on Youtube are able to create something as entertaining and visually stunning as a $250 million James Cameron Avatar film?
This is most certainly NOT coming in the next few years, but might it be possible in the 2030s?
We can logically extrapolate with near certainty that the world in the 2030s will be unrecognizable compared to today. Might this be one of the ways in which it is so?
Closing thoughts part 2
The obvious winners of this transition include:
Creators and the creator economy
Platform operators - likely to be companies that control operating systems and which have massive distribution networks
The data center base-layer (AWS, Azure, Google Cloud)
Semiconductors - can you imagine how much compute will be required in the future? You probably can’t - I don’t think I can either.
Consumers
Obvious losers include:
Actors. You won’t need human actors in the future.
Hollywood, Disney, Netflix & other content producing powerhouses
Gaming studios (for the same reason)
Legacy media
The hypothetical Elysian Simulator product I described is something we very well might have in the 2030s. Something like that would obviously have many more use cases that I didn’t describe. Take education for example.
One of the things elite private schools are doing today is customizing curriculums around the interests of each child. Instead of teaching the same thing to 20 different students, each student gets their own curriculum which is re-designed every few months around whatever concept the student is most interested in at the time.
For example, if a 7 year old is interested in dinosaurs then a curriculum will be built to teach math by having them count dinosaur eggs and measure the length of a Tyrannosaurus Rex. Children learn - literally - more than twice as fast if they are interested in the subject matter.
In the future you won’t need a private school that costs $50,000 per year to do this. All you will need is a subscription to the Elysian Simulator. Here’s the workflow.
Mother says to child: “I see that you are really enjoying playing with your race cars - would you like to learn about race cars today?”
Child says: “Yes please!”
Mother opens the Elysian Simulator and says: “Simulator, continue yesterday’s math class but instead of using dinosaurs use race cars”.
The simulator already knows from prior interactions that the child is working on multiplication tables, so it designs - on the spot - a new lesson to teach multiplication using race cars instead of dinosaurs.
I don’t know what the market size of a product like the Elysian Simulator would be - but I can imagine the educational tool in particular being so powerful that governments would pay for every child in the country to have access, because not having access would result in unimaginable levels of inequality if such a thing weren’t available to everyone regardless of their income and ability to pay for it.
The future is going to be wild. We are living on the knee of the curve of exponential progress.
Ben, great writing. So freaking cool! 🤘
Incredible storytelling to start this one.